RESEARCH
3D Shape Completion
This page presents a novel learning-based and weakly-supervised approach to 3D shape completion of point clouds. Specifically, a shape prior enables to learn shape completion without access to ground truth shapes, as relevant in many scenarios including autonomous driving, 3D scene understanding or surface reconstruction. Below, a more detailed abstract can be found. Additionally, this page provides the full CVPR'18 paper as well as the source code and two new synthetic shape completion benchmarks.
This work received the MINT-Award IT 2018!
Quick links: Master Thesis | CVPR Paper | 3-Page Summary | CVPR Poster | BibTex | Code & Data
Update. Improved results and updated benchmarks can be found on the project page of our latest ArXiv pre-print. Code and data are also available on GitHub.
Abstract
3D shape completion from partial point clouds is a fundamental problem in computer vision and computer graphics. Recent approaches can be characterized as either data-driven or learning-based. Data-driven approaches rely on a shape model whose parameters are optimized to fit the observations. Learning-based approaches, in contrast, avoid the expensive optimization step and instead directly predict the complete shape from the incomplete observations using deep neural networks. However, full supervision is required which is often not available in practice. In this work, we propose a weakly-supervised learning-based approach to 3D shape completion which neither requires slow optimization nor direct supervision. While we also learn a shape prior on synthetic data, we amortize, ie, learn, maximum likelihood fitting using deep neural networks resulting in efficient shape completion without sacrificing accuracy. Tackling 3D shape completion of cars on ShapeNet and KITTI, we demonstrate that the proposed amortized maximum likelihood approach is able to compete with a fully supervised baseline and a state-of-the-art data-driven approach while being significantly faster. On ModelNet, we additionally show that the approach is able to generalize to other object categories as well.
Download & Citing
The CVPR paper can be downloaded below; the supplementary material with additional experimental results and details on the setup is provided separately:
Paper (∼ 2.7MB)Supplementary (∼ 4.9MB)Poster (∼ 6.5MB)
@inproceedings{Stutz2018CVPR,
title = {Learning 3D Shape Completion from Laser Scan Data with Weak Supervision},
author = {David Stutz and Andreas Geiger},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
publisher = {IEEE Computer Society},
year = {2018}
}
The corresponding master thesis was awarded the MINT-Award IT 2018, sponsored by ZF, audimax and MINT Zukunft Schaffen. The 3-page summaryrequired by the award can be found below:



The corresponding master thesis can be found below:
Thesis (∼ 26.7MB)Slides (∼ 10.8MB)
@misc{Stutz2017,
author = {David Stutz},
title = {Learning Shape Completion from Bounding Boxes with CAD Shape Priors},
month = {September},
year = {2017},
institution = {RWTH Aachen University},
address = {Aachen, Germany},
howpublished = {http://davidstutz.de/},
}
Code, Data and Models
The code is bundled in the following repository and includes documentation, data and model download links as well as the LaTeX source of the paper:
Code on GitHubThe repository itself contains several sub-repositories:
| Repository | |
|---|---|
| daml-shape-completion | Shape completion implementations: amortized maximum likelihood (AML) (including the VAE shape prior), maximum likelihood (ML), Engelmann et al. [], and the supervised baseline (Sup). Implementations are mostly in Torch and C++ (for []). Installation requirements and usage instructions are included. |
| mesh-evaluation | Efficient C++ implementation of mesh-to-mesh distance (accuracy and completeness) as well as mesh-to-point distance; this tool can be used for evaluation. |
| bpy-visualization-utils | Python and Blender tools for visualization of meshes, occupancy grids and point clouds. These tools have been used for visualizations as presented in the paper. |
The data can be downloaded below; documentation is available as part of the main repository.
| Download | Links | |
|---|---|---|
| SN-clean (∼ 5.3GB) | Amazon AWS MPI-INF | This is the "clean" version of our ShapeNet benchmark; which means that we synthetically generated observations without noise which can be used to benchmark shape completion methods. |
| SN-noisy (∼ 3.8GB) | Amazon AWS MPI-INF | The "noisy" version of our ShapeNet benchmark, where we synthetically added noise similar to real data, for example on KITTI. |
| KITTI (∼ 2.5GB) | Amazon AWS MPI-INF | Our benchmark derived from KITTI; it uses the ground truth 3D bounding boxes to extract observations from the LiDAR point clouds. It does not include ground truth shapes; however, we tried to generate an alternative by considering the same bounding boxes in different timesteps. |
Pre-trained models of the proposed approach as well as the evaluated baselines can be downloaded below; documentation for running the pre-trained models is included in the main repository:
| Download | Links | |
|---|---|---|
| Models (∼ 224MB) | Amazon AWS MPI-INF | Pre-trained Torch models for the proposed amortized maximum likelihood (AML) approach (including the shape prior) and the fully-supervised baseline (Sup). |
News & Updates
Nov 30, 2018. Data and models are now also available through a server provided by MPI-INF.
May 24, 2018. Our pre-trained models are now available as download; see download links above.
May 18, 2018. Follow-up pre-print now on ArXiv: abs/1805.07290.
May 15, 2018. Source code and data are now available on GitHub. All resources can be found in one place within our main repository, davidstutz/cvpr2018-shape-completion; alternatively, our implementation can be found at davidstutz/daml-shape-completion, including data. The code also includes utilities for evaluation and visualization.
Apr 12, 2018. The LaTeX source of the CVPR'18 paper and the thesis is now available on GitHub: davidstutz/master-thesis-shape-completion, davidstutz/cvpr2018-shape-completion.
Apr 11, 2018. The CVPR'18 paper and my master thesis are now available as PDF. This project page, as well as the official project page went live.
Method
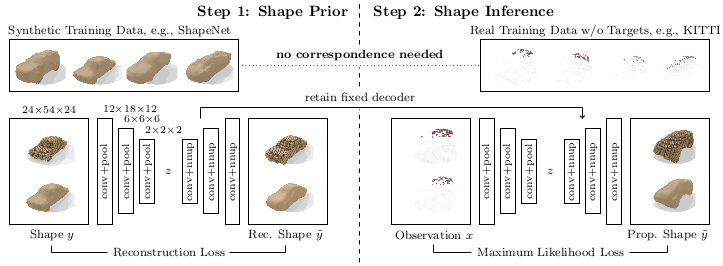
Figure 1 (click to enlarge): Overview of the proposed, weakly-supervised 3D shape completion approach; see text for details.
We focus on the problem of inferring and completing 3D shapes based on sparse and noisy 3D point observations as illustrated in Figure 1. Existing approaches to shape completion can be into data-driven and learning-based methods. The former usually rely on learned shape priors and formulate shape completion as optimization problem over the corresponding (lower-dimensional) latent space [][][]. Learning-based approaches, in contrast, assume a fully supervised setting in order to directly learn shape completion on synthetic data [][][][][][]. In the paper, we tackle the problems of both approaches -- the optimization problem of data-driven approaches and the required supervision of learning-based approaches -- in order to combine their strengths -- applicability to real data and efficient inference.
To this end, we propose an amortized maximum likelihood approach for 3D shape completion. More specifically, we first learn a shape model on synthetic data using a variational auto-encoder (Figure 1, step 1). Shape completion can then be formulated as maximum likelihood problem -- in the spirit of []. Instead of maximizing the likelihood independently for distinct observations, however, we follow the idea of amortized inference and learn to predict the maximum likelihood solutions directly given the observations. Towards this goal, we train a new encoder which embeds the observations in the same latent space using an unsupervised maximum likelihood loss (Figure 1, step 2). This allows us to learn 3D shape completion in challenging real-world situations, e.g., on KITTI []. For experimental evaluation, we introduce two novel, synthetic shape completion benchmarks based on ShapeNet [] and ModelNet []. On KITTI, we further compare our approach to the work of Engelmann et al. [] -- the only related work which addresses shape completion on KITTI. Our experiments demonstrate that we obtain shape reconstructions which rival data-driven techniques while significantly reducing inference time.
Experiments

Figure 2 (click to enlarge): Qualitative results on ShapeNet and KITTI, comparing against [] as well as a maximum likelihood (ML) baseline and a fully-supervised baseline (Sup). The proposed approach, amortized maximum likelihood is abbreviated as AML.
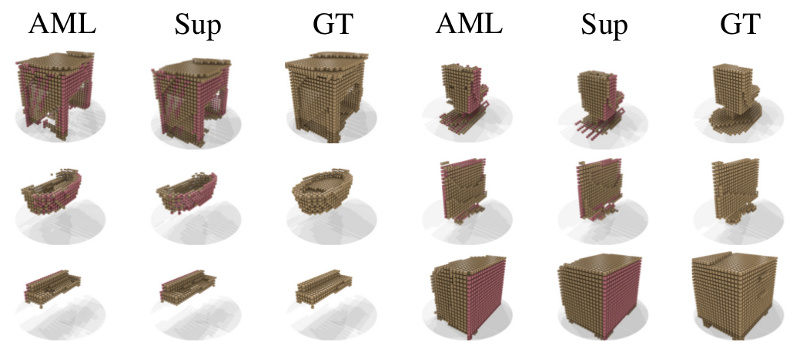
Figure 3 (click to enlarge): Qualitative results on ModelNet, where our AML model is trained on all ten classes. We compare against our supervised baseline (Sup) on occupancy grids only.
Figures 2 and 3 show qualitative results of the proposed amortized maximum likelihood (AML) approach to shape completion. We compare against a maximum likelihood (ML) baseline, [] and a supervised baseline (Sup) — see the paper for details. The qualitative results illustrate that our approach is competitive to fully-supervised approaches while only using a fraction of the supervision. Similarly, we show that AML is able to generalize across object categories and is able to correctly identify object categories based on sparse observations. Additionally, our approach is shown to outperform [] while being significantly faster.
Conclusion
We presented a weakly-supervised, learning-based approach to 3D shape completion. After using a variational auto-encoder to learn a shape prior on synthetic data, we formulated shape completion as maximum likelihood problem. We fixed the learned generative model and trained a new, deterministic encoder to amortize the ML problem. This encoder can be trained in an unsupervised fashion. On ShapeNet and ModelNet, we demonstrated that our approach outperforms a state-of-the-art data-driven method [] (while significantly reducing runtime) and generalizes across object categories. We also showed that it is able to compete with the fully-supervised model both quantitatively and qualitatively while using 9% or less supervision. We also demonstrated the applicability to real data on KITTI. Overall, our experiments demonstrate the benefits of the proposed approach: reduced runtime compared to data-driven approaches and training on unlabeled, real data compared to learning-based approaches.
Acknowledgements
As this work was part of a master thesis, written at the Autonomous Vision Group at Max Planck Institute for Intelligent System, I want to thank Prof. Andreas Geiger for making this work possible. From RWTH Aachen University, Prof. Bastian Leibe supported this thesis.
We also thank Francis Engelmann for help with [].
References
- [] S. Bao, M. Chandraker, Y. Lin, and S. Savarese. Dense object reconstruction with semantic priors. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2013.
- [] A. Dame, V. Prisacariu, C. Ren, and I. Reid. Dense reconstruction using 3D object shape priors. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2013.
- [] F. Engelmann, J. St ̈uckler, and B. Leibe. Joint object pose estimation and shape reconstruction in urban street scenes using 3D shape priors. In Proc. of the German Conference on Pattern Recognition (GCPR), 2016.
- [] A. Dai, C. R. Qi, and M. Nießner. Shape completion using 3d-encoder-predictor cnns and shape synthesis. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017.
- [] H. Fan, H. Su, and L. J. Guibas. A point set generation network for 3d object reconstruction from a single image. arXiv.org, abs/1612.00603, 2016.
- [] D. J. Rezende, S. M. A. Eslami, S. Mohamed, P. Battaglia, M. Jaderberg, and N. Heess. Unsupervised learning of 3d structure from images. arXiv.org, 1607.00662, 2016.
- [] G. Riegler, A. O. Ulusoy, H. Bischof, and A. Geiger. OctNetFusion: Learning depth fusion from data. In Proc. of the International Conf. on 3D Vision (3DV), 2017.
- [] A. Sharma, O. Grau, and M. Fritz. Vconv-dae: Deep volumetric shape learning without object labels. arXiv.org, 1604.03755, 2016.
- [] E. Smith and D. Meger. Improved adversarial systems for 3d object generation and reconstruction. arXiv.org, abs/1707.09557, 2017.
- [] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2012.
- [] A. X. Chang, T. A. Funkhouser, L. J. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, J. Xiao, L. Yi, and F. Yu. Shapenet: An information-rich 3d model repository. arXiv.org, 1512.03012, 2015.
- [] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2015.