In several recent papers [][][], researchers proposed neural network architectures for learning on unordered point clouds. In [], shape classification and segmentation is performed by computing per-point features using a succession of multi-layer perceptrons which are finally max- or average-pooled into one large vector. This pooling layer ensures that the network is invariant to the order of the input points. In [], in contrast, a network predicting point clouds is proposed for single-image 3D reconstruction. Both approaches are illustrated in Figure 1.
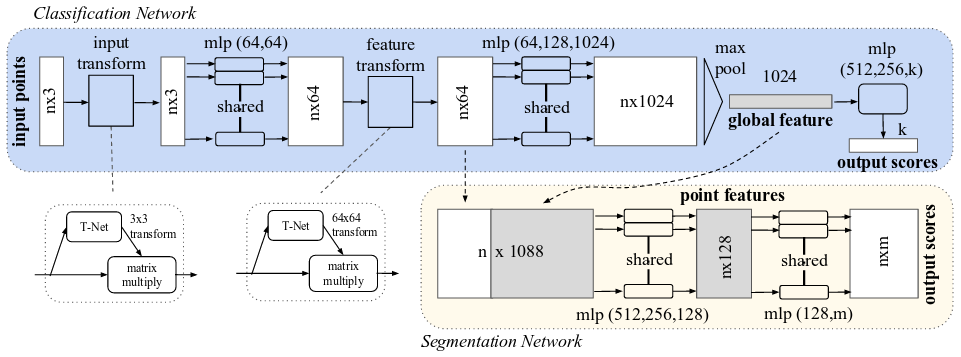
(a) Illustration of the PointNet architecture for shape classification and segmentation as discussed in [].

(b) Illustration of the point set generation network as proposed in [].
Figure 1 (click to enlarge): Illustrations of the PointNet and point set generation networks.
As part of my master thesis I experimented with a PointNet auto-encoder which combines the encoder from [] and the decoder from [] to learn how to reconstruct point clouds. While there are implementations from the authors available, I wanted to have a custom implementation in Torch for experimentation. The implementation can be found on GitHub:
PointNet Auto-Encoder on GitHubNote that the code was not thoroughly tested; and as discussed below, training is not necessarily stable.
Details
As indicated above, the main problem of deep learning on point clouds is their unordered nature. In [], Qi et al. propose a solution based on pooling. In particular, they argue that any function $f(\{x_1,\ldots,x_n\})$ on a set of points $\{x_1,\ldots,x_n\}$ can be approximated using a point-wise function $h$ and a symmetric function $g$:
$f(\{x_1,\ldots,x_n\}) \approx g(h(x_1),\ldots,g(h(x_n))$.
In practice, the point-wise function $h$ can be learned using a multi-layer perceptron and the symmetric function $g$ may be a symmetric pooling operation such as max- or average-pooling.
In Torch this can be implemented as follows:
-- Input is a N x 3 "image" with N being the number of points. -- The first few convolution layers basically represent the point-wise multi-layer perceptron. local model = nn.Sequential() model:add(nn.SpatialConvolution(1, 128, 1, 1, 1, 1, 0, 0)) model:add(nn.ReLU(true)) model:add(nn.SpatialBatchNormalization(128)) model:add(nn.SpatialConvolution(128, 256, 3, 1, 1, 1, 0, 0)) model:add(nn.ReLU(true)) model:add(nn.SpatialBatchNormalization(256)) model:add(nn.SpatialConvolution(256, 256, 1, 1, 1, 1, 0, 0)) model:add(nn.ReLU(true)) model:add(nn.SpatialBatchNormalization(256)) -- Average pooling, i.e. the symmetric function g. -- Can be replaced by max pooling. model:add(nn.SpatialAveragePooling(1, 1000, 1, 1, 0, 0)) -- Note that we assume 1000 points. model:add(nn.SpatialFullConvolution(256, 256, 1, 1000, 1, 1, 0, 0)) model:add(nn.ReLU(true)) model:add(nn.SpatialBatchNormalization(256)) model:add(nn.SpatialConvolution(256, 128, 1, 1, 1, 1, 0, 0)) model:add(nn.ReLU(true)) model:add(nn.SpatialBatchNormalization(128)) model:add(nn.SpatialFullConvolution(128, 128, 3, 1, 1, 1, 0, 0)) model:add(nn.ReLU(true)) model:add(nn.SpatialBatchNormalization(128)) model:add(nn.SpatialConvolution(128, 1, 1, 1, 1, 1, 0, 0))
Note that the point-wise function $h$ is implemented using several convolutional layers. With the correct kernel size, these are used to easily implement the point-wise multi-layer perceptron with shared weights across points. As a result, the input point cloud is provided as $N \times 3$ image; in the above example $1000$ points are assumed to be provided. As symmetric function $g$, an average pooling layer is used; a subsequent convolutional layer inflates the pooled features in order to predict a point cloud.
Given a network as shown above, the loss used for training also needs to be invariant to the order of the points. To this end, a symmetric nearest point distance can be used; in [], Qi et al. refer to this approach as Chamfer distance, which can be computed as follows:
$\mathcal{L}(\{\tilde{x}_1, \ldots, \tilde{x}_n\}, \{x_1,\ldots,x_n\}) = \frac{1}{2}\left(\sum_{i = 1}^n \min_{i'} \|x_i - x_{i'}\|_2^2 + \sum_{i' = 1}^n \min_{i} \|x_i - x_{i'}\|_2^2\right)$
As alternative to the squared distance used above, any other differentiable distance can be used.
For Torch, I implemented the Chamfer distance as above as well as a smooth $L_1$ Chamfer distance in C and CUDA and provide interfaces to Torch in form of a nn module:
--criterion = nn.ChamferDistanceCriterion() criterion = nn.SmoothL1ChamferDistanceCriterion() criterion.sizeAverage = false criterion = criterion:cuda()
A full example can be found on GitHub.
Discussion
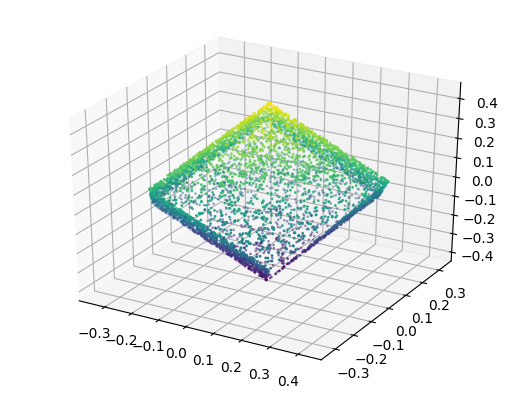

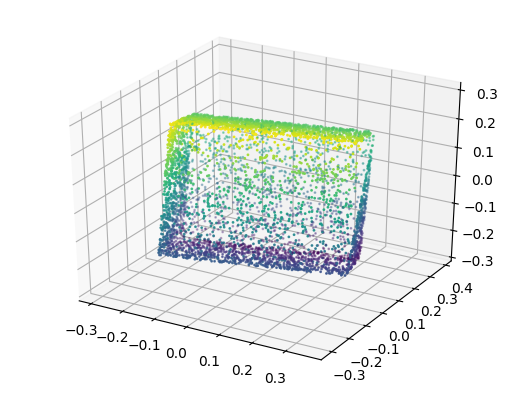

Figure 2 (click to enlarge): qualitative results of targets (left) and predictions (right). Note that we predicted $1000$ points; for the ground truth, however, we show $5000$ points.
Figure 2 shows some qualitative results on a dataset of rotated and slightly translated cuboids. In general, I found that these auto-encoders are difficult to train. For example, when adding a linear layer after pooling — to compute a low-dimensional bottleneck — training becomes significantly more difficult, such that the network often predicts a "mean point cloud". Similarly, the network architecture has a significant influence on training.
- [] Charles Ruizhongtai Qi, Hao Su, Kaichun Mo, Leonidas J. Guibas. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. CoRR abs/1612.00593 (2016).
- [] Charles Ruizhongtai Qi, Li Yi, Hao Su, Leonidas J. Guibas. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. CoRR abs/1706.02413 (2017).
- [] Haoqiang Fan, Hao Su, Leonidas J. Guibas. A Point Set Generation Network for 3D Object Reconstruction from a Single Image. CoRR abs/1612.00603 (2016).