Abstract
Check out the paper on ArXiv.
Adversarial training (AT), i.e., training on adversarial examples generating on-the-fly, is standard to obtain robust models within a specific threat model, e.g., $L_\infty$ adversarial examples. However, it has been shown that the obtained robustness does not generalize to attacks not seen during training such as larger $L_\infty$ perturbations or other $L_p$ threat models. Additionally, AT is known to reduce accuracy on clean examples. In this talk, I introduce Confidence-calibrated adversarial training (CCAT): CCAT tackles both problems by biasing the network towards low-confidence predictions on adversarial examples. By extrapolating low-confidence predictions beyond the $L_\infty$ adversarial examples seen during training, robustness generalizes to previously unseen attacks by rejecting low-confidence (adversarial) examples. Trained only on $L_\infty$ adversarial examples, I demonstrate improved robustness against $L_2$, $L_1$ and $L_0$ adversarial examples as well as adversarial frames. Furthermore, compared to AT, accuracy is improved.
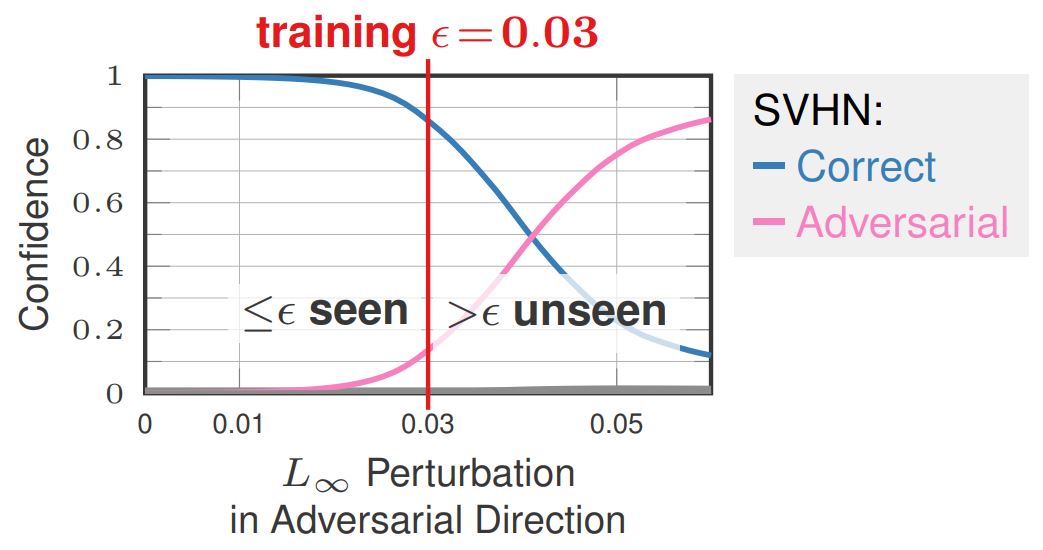

Figure 1: Illustration of how confidence-calibrated adversarial training (CCAT, right) tackles the problems of poor generalization of the obtained robustness of standard adversarial training (AT, left).
Talk
The slides of the talk can be found below:
Slides