Abstract
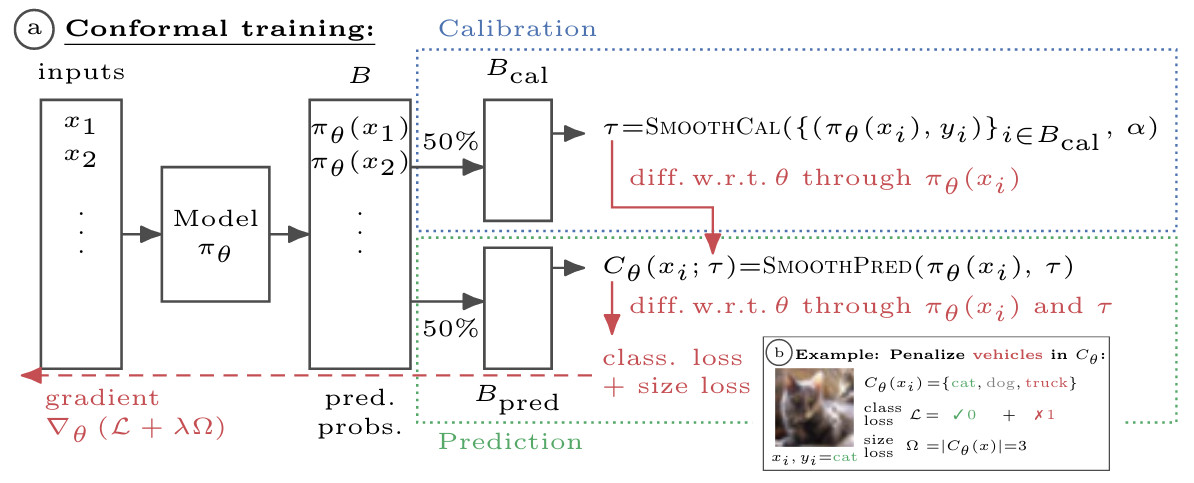
Figure 1: Coanformal prediction (CP) usually wraps any classifier $\pi_\theta(x)$ and constructs a confidence set $C_\theta$ with coverage guarantees. We develop differentiable prediction and calibration implementations for conformal prediction, allowing to "simulate" CP on each mini-batch $B$ during training. This so-called Conformal training (ConfTR) (a) calibrates on the first half of the batch and predicts confidence sets on the other half. This allows to optimize abritrary losses on the predicted confidence sets, e.g., to reduce average confidence set size or penalize specific classes from being included (b).
Modern deep learning based classifiers show very high accuracy on test data but this does not provide sufficient guarantees for safe deployment, especially in high-stake AI applications such as medical diagnosis. Usually, predictions are obtained without a reliable uncertainty estimate or a formal guarantee. Conformal prediction (CP) addresses these issues by using the classifier's probability estimates to predict confidence sets containing the true class with a user-specified probability. However, using CP as a separate processing step after training prevents the underlying model from adapting to the prediction of confidence sets. Thus, this paper explores strategies to differentiate through CP during training with the goal of training model with the conformal wrapper end-to-end. In our approach, conformal training (ConfTr), we specifically "simulate" conformalization on mini-batches during training. We show that CT outperforms state-of-the-art CP methods for classification by reducing the average confidence set size (inefficiency). Moreover, it allows to "shape" the confidence sets predicted at test time, which is difficult for standard CP. On experiments with several datasets, we show ConfTr can influence how inefficiency is distributed across classes, or guide the composition of confidence sets in terms of the included classes, while retaining the guarantees offered by CP.
Paper on ArXiv
@article{Stutz2021ARXIV,
author = {David Stutz and Krishnamurthy and Dvijotham and Ali Taylan Cemgil and Arnaud Doucet},
title = {Learning Optimal Conformal Classifiers},
year = {2021},
volume = {abs/2110.09192},
journal = {CoRR},
}