Abstract
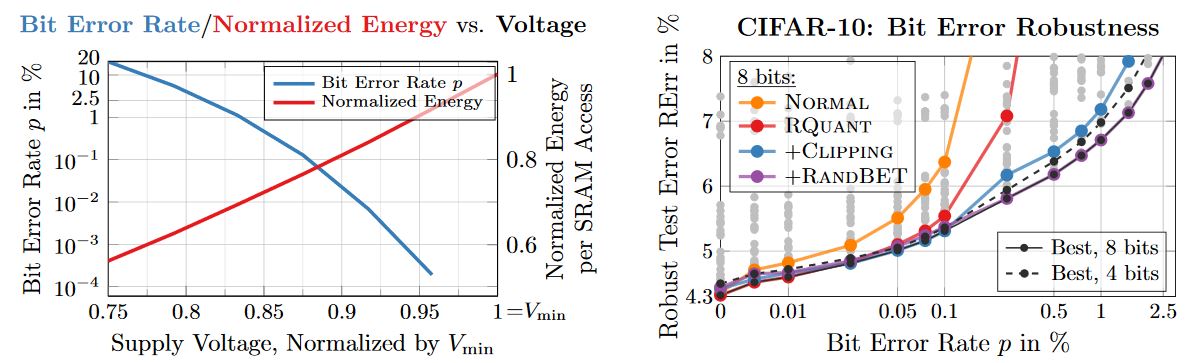
Figure 1: Left: Average bit error rate (blut) and energy (red) against voltage. These are measurements from 32 14nm SRAM arrays of size $512\times64$. Both voltage and energy per SRAM access are normalized to $V_{\text{min}}$, the minimum voltage with error free operation (determined experimentally). SRAM accesses havesignificant impact on the DNN accelerators overall energy consumption, however, reducing voltage causes an exponential increase in bit errors. Right: Robust test error (test error after injecting bit errors) plotted against bit error rates. For $8$ bit quantization, robust fixed-point quantization, training with weight clipping and finally adding random bit error training improves robustness significantly.
Deep neural network (DNN) accelerators received considerable attention in past years due to saved energy compared to mainstream hardware. Low-voltage operation of DNN accelerators allows to further reduce energy consumption significantly, however, causes bit-level failures in the memory storing the quantized DNN weights. In this paper, we show that a combination of robust fixed-point quantization, weight clipping, and random bit error training (RandBET) improves robustness against random bit errors in (quantized) DNN weights significantly. This leads to high energy savings from both low-voltage operation as well as low-precision quantization. Our approach generalizes across operating voltages and accelerators, as demonstrated on bit errors from profiled SRAM arrays. We also discuss why weight clipping alone is already a quite effective way to achieve robustness against bit errors. Moreover, we specifically discuss the involved trade-offs regarding accuracy, robustness and precision: Without losing more than 1% in accuracy compared to a normally trained 8-bit DNN, we can reduce energy consumption on CIFAR-10 by 20%. Higher energy savings of, e.g., 30%, are possible at the cost of 2.5% accuracy, even for 4-bit DNNs.
Paper on ArXiv
@article{Stutz2020ARXIV,
author = {David Stutz and Nandhini Chandramoorthy and Matthias Hein and Bernt Schiele},
title = {Bit Error Robustness for Energy-Efficient DNN Accelerators},
journal = {CoRR},
volume = {abs/2006.13977},
year = {2020}
}
Updates from Previous Version
Compared to the original ArXiv pre-print from June 2020, this version does not consider robustness against adversarial bit errors in quantized DNN weights.
Regarding random bit error robustness, this paper includes:
- A thorough evaluation of different fixed-point quantization schemes in terms of random bit error robustness, resulting in our robust fixed-point quantization.
- More details and analysis on the benefit of weight clipping during training. During training, the weights are regularized by clipping them to a small range $[-w_{\text{max}}, w_{\text{max}}]$. We find that this improves robustness through redundancy in weights.
- Combined with random bit error training, our robust fixed-point quantization and weight clipping obtains significant robustness improvements. The robustness generalizes to real, profiled bit errors even if the profiled bit error distribution deviates significantly from our bit error model.
- The obtained robustness, allowing low-voltage operation, can also be combined with low-precision models, e.g., $4$ bit on Cifar10 or "$2$ bit on MNIST, further reducing energy consumption.