This paper was accepted at ICML'20!.
This is a substantial update to the previous version, including additional experiments with $L_2$, $L_1$ and $L_0$ adversarial examples as well as adversarial frames.
Abstract
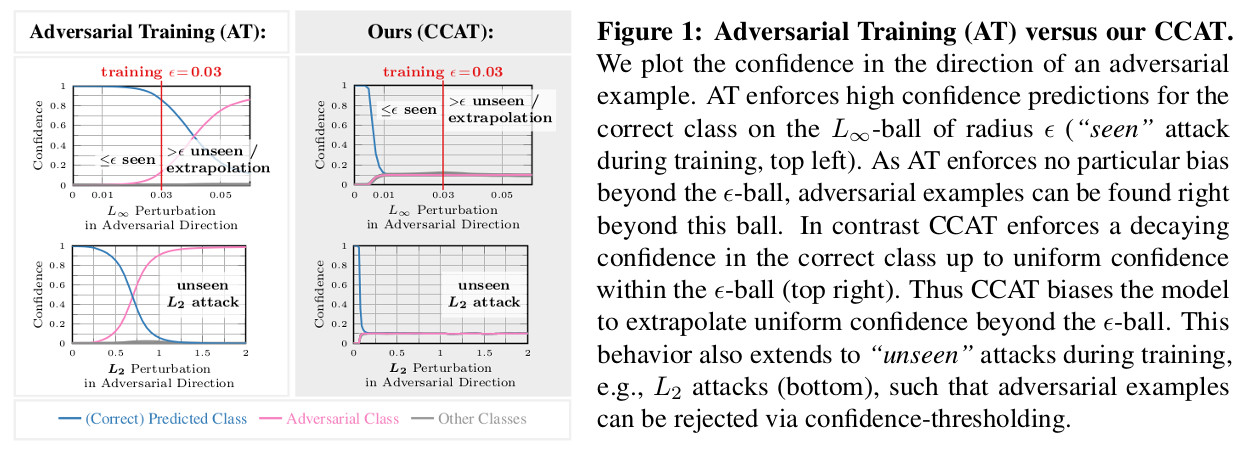
Adversarial training yields robust models against a specific threat model, e.g., $L_\infty$ adversarial examples. Typically robustness does not generalize to previously unseen threat models, e.g., other $L_p$ norms, or larger perturbations. Our confidence-calibrated adversarial training (CCAT) tackles this problem by biasing the model towards low confidence predictions on adversarial examples. By allowing to reject examples with low confidence, robustness generalizes beyond the threat model employed during training. CCAT, trained only on $L_\infty$ adversarial examples, increases robustness against larger $L_\infty$, $L_2$, $L_1$ and $L_0$ attacks, adversarial frames, distal adversarial examples and corrupted examples and yields better clean accuracy compared to adversarial training. For thorough evaluation we developed novel white- and black-box attacks directly attacking CCAT by maximizing confidence. For each threat model, we use $7$ attacks with up to $50$ restarts and $5000$ iterations and report worst-case robust test error, extended to our confidence-thresholded setting, across all attacks.
Paper on ArXiv
@article{Stutz2019ARXIV,
author = {David Stutz and Matthias Hein and Bernt Schiele},
title = {Confidence-Calibrated Adversarial Training: Generalizing to Unseen Attacks},
journal = {CoRR},
volume = {abs/1910.06259},
year = {2019}
}
Updates from Previous Versions
Besides significantly improved writing, the paper includes the following improvements:
- Results with additional $L_2$, $L_1$ and $L_0$ attacks, including the Square attack [], the Corner Search attack [], the Geometry attack [].
- Results with adversarial frames [].
- Comparison to the multi-steepest descent (MSD) adversarial training [], i.e., training with $L_\infty$, $L_2$ and $L_1$ adversarial examples.
- Comparison to the Mahalanobis and Local Intrinsic Dimentionality detectors [][], which were "cracked" using our thorough evaluation.
The code, including training procedures and all attacks, to reproduce the results in the paper will be provided on GitHub soon.
- [] Andriushchenko, M., Croce, F., Flammarion, N., and Hein, M. Square attack: a query-efficient black-box adversarial attack via random search. arXiv.org, 1912.00049, 2019.
- [] Croce, F. and Hein, M. Sparse and imperceivable adversarial attacks. arXiv.org, abs/1909.05040, 2019.
- [] Khoury, M. and Hadfield-Menell, D. On the geometry of adversarial examples. arXiv.org, abs/1811.00525, 2018.
- [] Zajac, M., Zolna, K., Rostamzadeh, N., and Pinheiro, P. O. Adversarial framing for image and video classification. In AAAI Workshops, 2019.
- [] Maini, P., Wong, E., and Kolter, J. Z. Adversarial robustness against the union of multiple perturbation models. arXiv.org, abs/1909.04068, 2019.
- [] Lee, K., Lee, K., Lee, H., and Shin, J. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In NeurIPS, 2018.
- [] Ma, X., Li, B., Wang, Y., Erfani, S. M., Wijewickrema, S. N. R., Schoenebeck, G., Song, D., Houle, M. E., and Bailey, J. Characterizing adversarial subspaces using local intrinsic dimensionality. In ICLR, 2018.