Last semester, I had the great opportunity to work — as part of my master thesis — with Andreas Geiger. During my time in Tübingen, I also had the chance to help establish a new benchmark as part of the KITTI dataset []: a 3D object detection benchmark. This was also a perfect opportunity to look behind the scenes of KITTI, get more familiar with the raw data and think about the difficulties involved when evaluating object detectors. In this article, I want to share a rough overview of the new benchmark and share some important insights to simplify submissions.
Acknowledgements. I want to note that my contribution to KITTI's 3D object detection benchmark is limited. Large parts of the evaluation code was written by Bo Li and Xiaozhi Chen. Additionally, most of the backend infrastructure was already provided and only needed to be adapted accordingly. Overall, I was responsible for putting everything together, testing and tweaking the evaluation code and the submission process.
Overview


The 3D object detection benchmark comes in two flavors: the actual 3D object detection benchmark using 3D bounding box overlap to determine true/false positives/negatives and the bird's eye view benchmark using 2D bounding box overlap in bird's eye view for evaluation — illustrated in Figure 1. Both benchmarks are coupled meaning that any submission including 3D bounding boxes will be evaluated in both settings.
Data
The submission process follows the 2D object detection benchmark, as does the training/test split as well as the available data — meaning images (potentially including the three temporally preceding/following frames) and velodyne point clouds. As the velodyne point clouds might be crucial to develop a good 3D object detector, I want to make some important notes that can potentially save some hours of debugging. First, however, I refer to the IJRR paper [] which also details some of these points.
When using both images and velodyne point clouds — and training with the ground truth 3D bounding boxes — coordinate systems become important. Both the 3D bounding boxes and the point clouds are in the same coordinate system — corresponding to the image. The paper [1] details this in section 4; while in the same coordinate system, the axes differ:
- Camera: x = right, y = down, z = forward;
- Velodyne: x = forward, y = left, z = up.
In order to work with the 3D bounding boxes in the velodyne point clouds, they have to be adapted to the corresponding coordinate system. When also using the raw data, for example the raw point clouds (which would enable to fuse point clouds over multiple time steps), it is important to remember that these are in a different coordinate system; the difference between the coordinate systems can be accounted for using the cam-to-velo transformation outlined in [1] (can be found in calib_velo_to_cam.txt).
Evaluation
Evaluation follows the 2D object detection benchmark regarding the different difficulty classes:
- Easy: minimum bounding box height = 40px; maximum occlusion: fully visible; maximum truncation: 0.15.
- Moderate: minimum bounding box height = 25px; maximum occlusion: partly occluded; maximum truncation: 0.3.
- Hard: minimum bounding box height = 25px; maximum occlusion: difficult to see; maximum truncation: 0.5.
This implies, that the 3D bounding boxes are filtered based on their 2D counterparts. This also means that a submission has to include both 2D and 3D bounding boxes! Additionally, occlusion and truncation is assessed on the image plane. Finally, only objects visible in the image plane are labeled. For fair evaluation, the submission should therefore not include any objects detected outside the range of view of the cameras — the evaluation script does not take care of this.
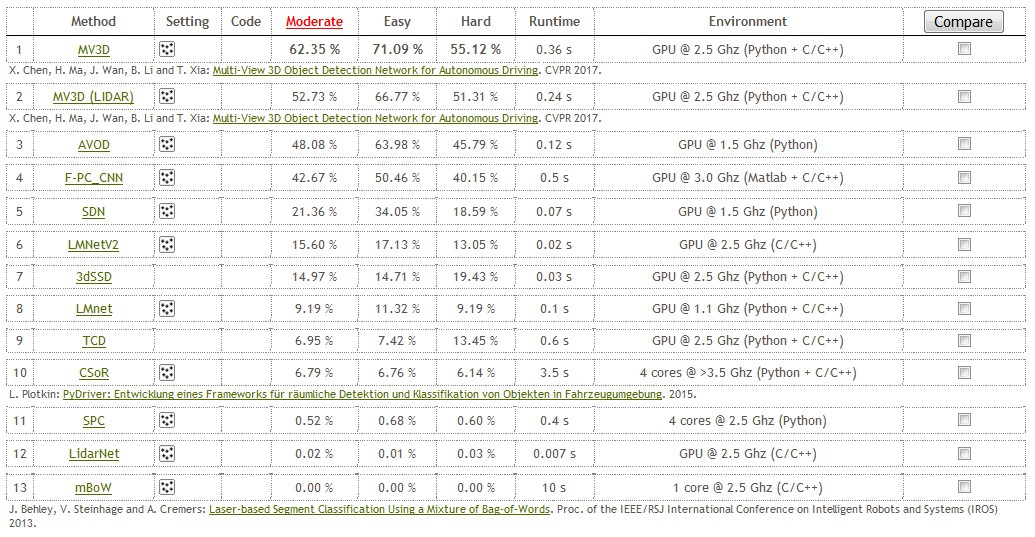
Results
Currently, only few approaches are evaluated on the 3D object detection benchmark. However, this also means that there is still room for improvement — after all, KITTI is a very hard dataset for accurate 3D object detection. The leaderboard for car detection, at the time of writing, is shown in Figure 2. Currently, MV3D [] is performing best; however, roughly 71% on easy difficulty is still far from perfect. Unfortunately, the list still includes many unpublished methods (the ones without publication).
- [] Andreas Geiger, Philip Lenz, Christoph Stiller, Raquel Urtasun. Vision meets robotics: The KITTI dataset. I. J. Robotics Res. 32(11), 2013.
- [] X. Chen, H. Ma, J. Wan, B. Li and T. Xia: Multi-View 3D Object Detection Network for Autonomous Driving. CVPR 2017.