Abstract
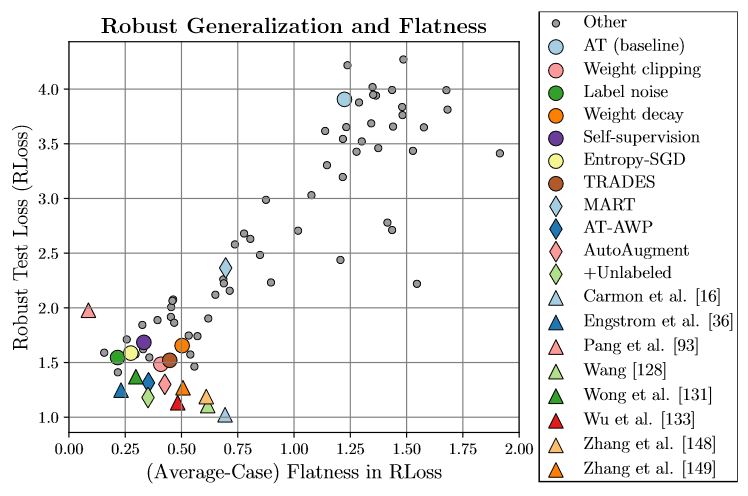
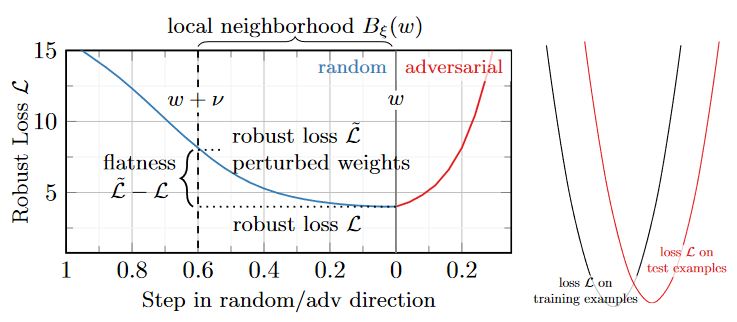
Figure 1: Left: Robust loss on adversarial examples (y-axis) against the proposed average-case flatness measure in the robust loss in weight space (lower is "flatter", x-axis). Popular AT variants such as TRADES correspond to flatter minima and, vice versa, explicitly regularizing flatness improves robustness. Middle: Illustration of measuring flatness in random (left, blue) or adverrsarial (right, red) directions by computing the difference between the robust loss $\hat{\mathcal{L}}$ after perturbing weights at $w + \nu$ and the reference robust loss $\mathcal{L}$ in a neighborhood $B_\xi(w)$. Right: Large changes in the robust loss landscape around the "sharp" minimum causes poor generalization from training to test examples.
Adversarial training (AT) has become the de-facto standard to obtain models robust against adversarial examples. However, AT exhibits severe robust overfitting: cross-entropy loss on adversarial examples, so-called robust loss, decreases continuously on training examples, while eventually increasing on test examples. In practice, this leads to poor robust generalization, i.e., adversarial robustness does not generalize well to new examples. In this paper, we study the relationship between robust generalization and flatness of the robust loss landscape in weight space, i.e., whether robust loss changes significantly when perturbing weights. To this end, we propose average- and worst-case metrics to measure flatness in the robust loss landscape and show a correlation between good robust generalization and flatness. For example, throughout training, flatness reduces significantly during overfitting such that early stopping effectively finds flatter minima in the robust loss landscape. Similarly, AT variants achieving higher adversarial robustness also correspond to flatter minima. This holds for many popular choices, e.g., AT-AWP, TRADES, MART, AT with self-supervision or additional unlabeled examples, as well as simple regularization techniques, e.g., AutoAugment, weight decay or label noise. For fair comparison across these approaches, our flatness measures are specifically designed to be scale-invariant and we conduct extensive experiments to validate our findings.
Paper on ArXiv
@article{Stutz2021ARXIV,
author = {David Stutz and Matthias Hein and Bernt Schiele},
title = {Relating Adversarially Robust Generalization to Flat Minima},
journal = {CoRR},
volume = {abs/2104.04448},
year = {2021}
}