Update. This paper has been accepted at IJCV! Find the paper here or see the corresponding article.
Abstract
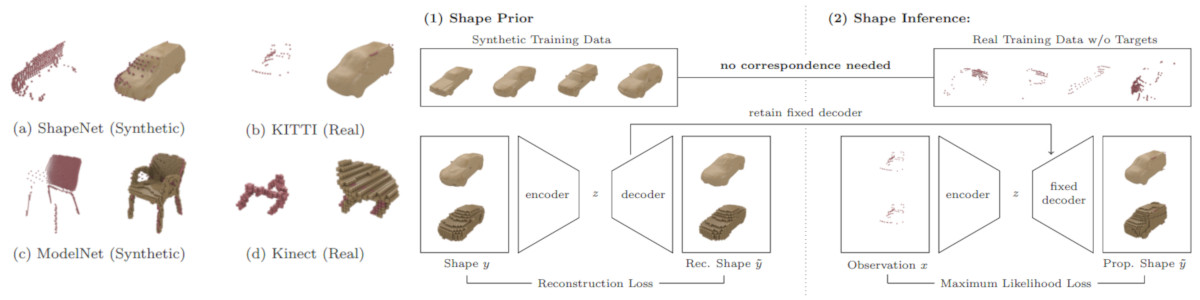
Figure 1 (click to enlarge): Overview of the proposed, weakly-supervised 3D shape completion approach; see the paper for details.
We address the problem of 3D shape completion from sparse and noisy point clouds, a fundamental problem in computer vision and robotics. Recent approaches are either data-driven or learning-based: Data-driven approaches rely on a shape model whose parameters are optimized to fit the observations; Learning-based approaches, in contrast, avoid the expensive optimization step by learning to directly predict complete shapes from incomplete observations in a fully-supervised setting. However, full supervision is often not available in practice. In this work, we propose a weakly-supervised learning-based approach to 3D shape completion which neither requires slow optimization nor direct supervision. While we also learn a shape prior on synthetic data, we amortize, i.e., learn, maximum likelihood fitting using deep neural networks resulting in efficient shape completion without sacrificing accuracy. On synthetic benchmarks based on ShapeNet [] and ModelNet [] as well as on real robotics data from KITTI [] and Kinect [], we demonstrate that the proposed amortized maximum likelihood approach is able to compete with the fully supervised baseline of [] and outperforms the data-driven approach of [], while requiring less supervision and being significantly faster.
Paper on ArXiv
@article{Stutz2018ARXIV,
author = {David Stutz and Andreas Geiger},
title = {Learning 3D Shape Completion under Weak Supervision},
journal = {CoRR},
volume = {abs/1805.07290},
year = {2018},
url = {http://arxiv.org/abs/1805.07290},
}
Comparison to CVPR'18

Figure 2 (click to enlarge): Experimental results on ShapeNet; results from our CVPR'18 work (top) and results from the pre-print (bottom). Note that more detailed shapes are predicted by the approach presented in the ArXiv pre-print. On the top, [7] corresponds to the work by Engelmann et al. []; shapes are shown in beige and observations in red.
This work is largely based on our CVPR'18 work. However, we improved the proposed shape completion method, the constructed datasets and present more extensive experiments. In particular, we extended our weakly-supervised amortized maximum likelihood approach to enforce more variety and increase visual quality significantly. On ShapeNet and ModelNet, we use volumetric fusion to obtain more detailed, watertight meshes and manually selected — per object-category — 220 high-quality models to synthesize challenging observations. Finally, we increased the spatial resolution and consider two additional baselines, [] and []. Some experimental results in comparison to our CVPR'18 work are shown in Figure 2.
- [] Dai A, Qi CR, Nießner M (2017) Shape completion using 3d-encoder-predictor cnns and shape synthesis. In: Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR).
- [] Engelmann F, St¨uckler J, Leibe B (2016) Joint object pose estimation and shape reconstruction in urban street scenes using 3D shape priors. In: Proc. of the German Conference on Pattern Recognition (GCPR).
- [] Gupta S, Arbel´aez PA, Girshick RB, Malik J (2015) Aligning 3D models to RGB-D images of cluttered scenes. In: Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR).
- [] Wu Z, Song S, Khosla A, Yu F, Zhang L, Tang X, Xiao J (2015) 3d shapenets: A deep representation for volumetric shapes. In: Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR).
- [] Chang AX, Funkhouser TA, Guibas LJ, Hanrahan P, Huang Q, Li Z, Savarese S, Savva M, Song S, Su H, Xiao J, Yi L, Yu F (2015) Shapenet: An information-rich 3d model repository. arXivorg 1512.03012.
- [] Geiger A, Lenz P, Urtasun R (2012) Are we ready for autonomous driving? The KITTI vision benchmark suite. In: Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR).
- [] Yang B, Rosa S, Markham A, Trigoni N, Wen H (2018) 3d object dense reconstruction from a single depth view. arXivorg abs/1802.00411.