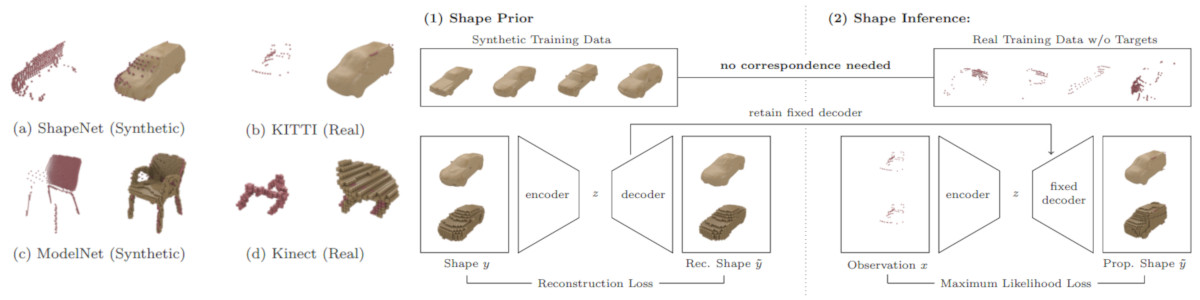
Figure 1 (click to enlarge): Overview of the proposed, weakly-supervised 3D shape completion approach.
In this pre-print, we improve upon our earlier CVPR'18 work on weakly-supervised 3D shape completion on ShapeNet [], KITTI [] and ModelNet []. In particular, we achieve higher-quality predictions and also present additional experiments as well as improved benchmarks.
The code and data is bundled in the following repository:
Code on GitHubThe paper is available on ArXiv:
Paper on ArXiv
@article{Stutz2018ARXIV,
author = {David Stutz and Andreas Geiger},
title = {Learning 3D Shape Completion under Weak Supervision},
journal = {CoRR},
volume = {abs/1805.07290},
year = {2018},
url = {http://arxiv.org/abs/1805.07290},
}
Code
The code is spread over multiple repositories that contain independent parts of the code but are included as sub-repositories:
| Repository | |
|---|---|
| aml-shape-completion | Shape completion implementations: amortized maximum likelihood (AML) (including the VAE [] shape prior), maximum likelihood (ML), Engelmann et al. [], Dai et al. [], iterative closest point (ICP) and the supervised baseline (Sup). Implementations are mostly in Torch and C++ (for []). Installation requirements and usage instructions are included. Note that the AML version in this repository obtains improved results over our CVPR'18 version at davidstutz/daml-shape-completion. |
| mesh-evaluation | Efficient C++ implementation of mesh-to-mesh distance (accuracy and completeness) as well as mesh-to-point distance; this tool can be used for evaluation. |
| bpy-visualization-utils | Python and Blender tools for visualization of meshes, occupancy grids and point clouds. These tools have been used for visualizations as presented in the paper. |
The above repositories contain the very essentials for reproducing the results reported in the paper. There are, however, some additional repositories containing related tools:
| Repository | |
|---|---|
| mesh-voxelization | Efficient C++ implementation for voxelizing watertight triangular meshes into occupancy grids and/or signed distance functions (SDFs). This tool was used to create the shape completion benchmarks as described below. |
| mesh-fusion | This is a Python implementation of TSDF Fusion similar to [] using and ; this approach was used to obtain simplified and watertight meshes for our synthetic benchmarks. |
Data
In our paper, we created three novel shape completion benchmarks: based on ShapeNet [], KITTI [] and ModelNet10 []. Here, we provide the data for the shape completion benchmark of cars derived from ShapeNet and KITTI. The corresponding download links can be found in the repository or the table below.
Except for ModelNet10 and Kinect, all downloads include benchmarks for three difference resolutions. On ShapeNet and KITTI, these are $24\times 54\times24$, $32\times72\times32$ and $48\times108\times48$. On ModelNet, these include $32^3$, $48^3$ and $64^3$.
| Download | |
|---|---|
|
ShapeNet: SN-clean SN-noisy |
The "clean" and "noisy" versions of our ShapeNet benchmark; which means that we synthetically generated observations without or with noise which can be used to benchmark shape completion methods. Note that this is not the same as for our CVPR'18 paper. |
| KITTI | Our benchmark derived from KITTI; it uses the ground truth 3D bounding boxes to extract observations from the LiDAR point clouds. It does not include ground truth shapes; however, we tried to generate an alternative by considering the same bounding boxes in different timesteps. Note that this is not the same as for our CVPR'18 paper. |
|
ModelNet: bathtubs chairs desks tables |
Single-category benchmarks derived from ModelNet's bathtubs, chairs, desks and tables. |
| ModelNet10 | Benchmark based on all ten categories from ModelNet10. |
For details on the data formats, the process of generating the data, please consult the repository.
Models
We also provide pre-trained models for the proposed approach and all baselines; the downloads include models on all datasets and for all resolutions.
| Download | |
|---|---|
| AML Models (∼ 2.8GB) | Pre-trained Torch models for the proposed amortized maximum likelihood (AML) approach. |
| Dai et al. [] Models (∼ 11.6GB) | Pre-trained Torch models for the fully-supervised baseline of Dai et al. []. |
| Supervised Baseline Models (∼ 1.6GB) | Pre-trained Torch models of our own fully-supervised baseline. |
| DVAE Shape Prior Models (∼ 2.3GB) | Pre-trained Torch models of our DVAE shape prior. |
- [] Dai A, Qi CR, Nießner M (2017) Shape completion using 3d-encoder-predictor cnns and shape synthesis. In: Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR).
- [] F. Engelmann, J. St ̈uckler, and B. Leibe. Joint object pose estimation and shape reconstruction in urban street scenes using 3D shape priors. In Proc. of the German Conference on Pattern Recognition (GCPR), 2016.
- [] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2012.
- [] A. X. Chang, T. A. Funkhouser, L. J. Guibas, P. Hanrahan, Q. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, J. Xiao, L. Yi, and F. Yu. Shapenet: An information-rich 3d model repository. arXiv.org, 1512.03012, 2015.
- [] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2015.
- [] Gernot Riegler, Ali Osman Ulusoy, Horst Bischof, Andreas Geiger: OctNetFusion: Learning Depth Fusion from Data. CoRR abs/1704.01047 (2017).