The problem of estimating intrinsic images, that is reflectance and shading, from a single image has already been addressed in 1971 by Land and McCann [1] as well as in 1978 by Barrow and Tenenbaum [4]. Researchers within the computer vision and image processing communities agree that solving this problem would be beneficial for many problems in vision and graphics. After discussing some related work and important datasets in the article Intrinsic Images – Introduction and Reading List, this article will introduce a mathematical formulation of the Retinex theory as originally developed by Land and McCann [1]. Further, we introduce the partial differential equation formalization given by Morel et al. [28] which can easily be implemented in practice.
Instead of discussing related work in detail, we simply point out some recent literature on intrinsic images [7,9-12,14-19,20] and intrinsic video (or image sequences) [21-27] as well as appropriate datasets [7,8,25,29,30].
Problem Formulation
Formally, we define the problem of intrinsic images as follows:
Problem. Given an input image
$I : \underline{H} = \{1,\ldots,H\} \times \underline{W} \mapsto \underline{255}^3$, with $N = HW$,
a set of images $I_1,\ldots,I_T$ or a video
$V : \underline{H} \times \underline{W} \times \underline{T} \mapsto \underline{255}^3$, with, $N = HWT$,
estimate the corresponding reflectance image $R$ and shading image $S$ for each input image.
Note that the problem of intrinsic images as originally stated by Barrow and Tenenbaum [4] also includes other intrinsic characteristics as for example depth, surface orientation, occlusion and motion boundaries or optical flow.
Retinex Theory and Algorithm
The Retinex theory was introduced by Land and McCann [1] in 1971 and is based on the assumption of a Mondrian world. This refers to the paintings by the dutch painter Piet Mondrian which, for example, look as depicted in figure 1. Land and McCann argue that human color sensation appears to be independent of the amount of light, that is the measured intensity, coming from observed surfaces [1]. Therefore, Land and McCann suspect an underlying characteristic guiding human color sensation [1]. Note that this characteristic is not directly related to the intrinsic images described by Barrow and Tenenbaum [4], however, as stated by Land and McCann, this characteristic has to be related to reflectance.
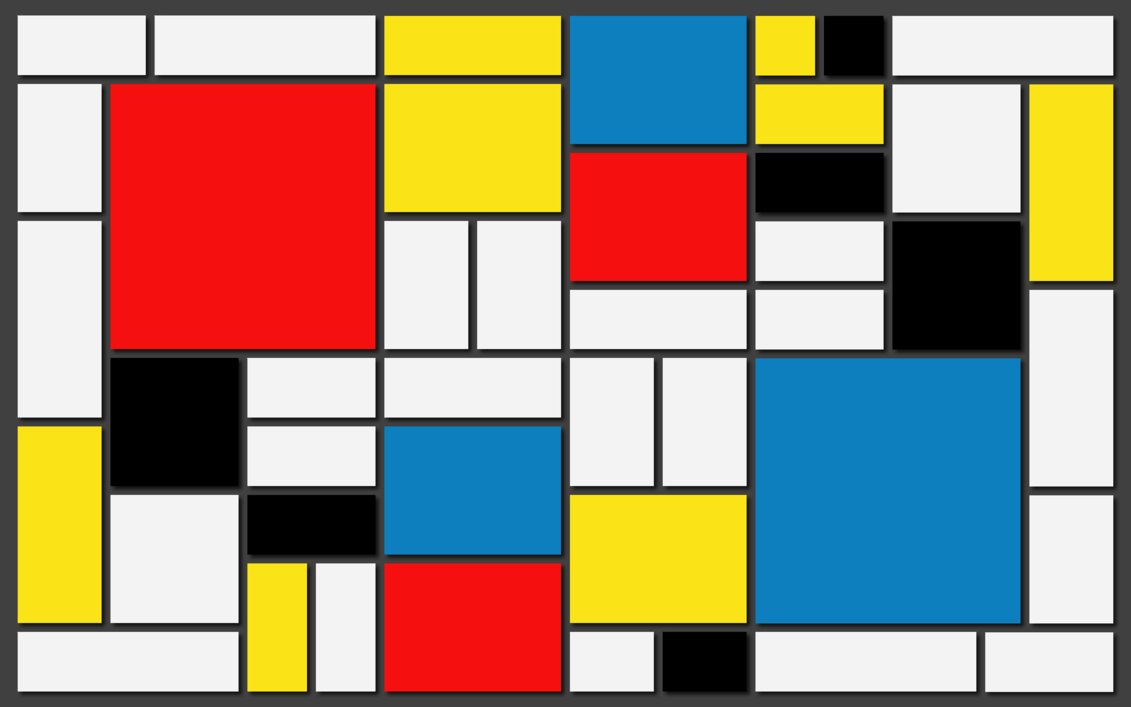
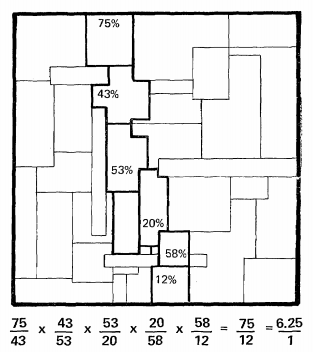
The intuition behind the Retinex theory, illustrated on the example of a Mondrian image with artificial, smooth shading, can be described as follows. The reflectance ratio of two selected patches within the Mondrian image can be determined by following a path between them. Along the path, we multiply the measured intensity ratios. At the border of patches, the intensity ratios will correspond to reflectance changes, while within the patches, the intensity ratios will be close to one. Land and McCann [1] propose to threshold these ratios to suppress intensity changes due to shading, which is assumed to be smooth. The final ratio will be equal to the actual reflectance ratio between the two patches.
The formalization of the described algorithm, as well as its extension to color images, is due to Horn [3] and Blake [5], however, we follow Morel et al. [28]. The reflectance for each pixel in channel $I_c$ is computed by considering a family $\{x_{k}\}_{k = 1}^{K_j} \subseteq \underline{H} \times \underline{W}$ of $J$ paths. For a given pxel $x_n \in \underline{H} \times \underline{W}$, all of these paths start at $x_n$ and end at an arbitrary pixel within the image. Then the reflectance $R_c(x_n)$ of pixel $x_n$ in channel $c$ is computed as
$R_c(x_n) = \frac{1}{J}\sum_{j = 1}^J \sum_{k = 1}^{K_j} \lambda\left(I_c(x_k) - I_c(x_{k + 1})\right)$(1).
where
$\lambda(x) = \left\{\begin{array}{l l}|x|&\quad\text{ if }|x| > \tau\\0&\quad\text{ else }\end{array}\right.$(2).
The main problem of this approach is the problem of choosing the paths $\{x_{k}\}_{k = 1}^{K_j}$ such that equation (1) both can be computed efficiently and calculates the proper reflectance (that is, a good approximations thereof).
Partial Differential Equation Formalization
Morel et al. [28] propose a partial differential equation formalization of the Retinex theory. We follow [28] and discuss both the basic framework and the practical implementation.
We consider a family of $J$ random paths $\{x_{k}\}_{k = 1}^{K_j} \subseteq \underline{H} \times \underline{W}$, each of which starts at pixel $x_n$ and ends at a randomly chosen pixel. The random paths are defined on the plane $\mathbb{Z}^2$, however, are reflected on the image borders, resulting in well-defined paths within the image plane. Then, the lightness of pixel $x_n$ in channel $I_c$, in analogy to equation (1), can be written as
$R_c(x_n) = \frac{1}{N}\sum_{j}^J \sum_{k = 1}^{K_j} \lambda\left(I_c(x_k) - I_c(x_{k + 1})\right)$.
Note that, in contrast to equation (1), this can be interpreted as expectation of the relative reflectance defined by one such random path [28].
Utilizing the random path framework, Morel et al. [28] show that the reflectance $R_c$ is the solution of the Poisson equation
$\left\{\begin{array}{l l}- \Delta R_c(x_n) = F_c(x_n)\quad &x_n \in \underline{H} \times \underline{W}\\\frac{\partial R_c}{\partial n} = 0\quad &x \in \partial(\underline{H} \times \underline{W})\end{array}\right.$(4)
with Neumann boundary condition where $\frac{\partial R_c}{\partial n}$ denotes the normal derivative and $\partial(\underline{H} \times \underline{W})$ denotes the boundary of $\underline{H} \times \underline{W}$. Here, $F_c(x)$ is defined as
$F_c(x_n)\label{eq:intrinsic-laplace} = \lambda\left(I_c(x_n) - I_c(x_{n,1} + 1, x_{n,2})\right) + \lambda\left(I_c(x_n) - I_c(x_{n,1} - 1, x_{n,2})\right)$
$ + \lambda\left(I_c(x_n) - I_c(x_{n,1}, x_{n,2} + 1)\right) + \lambda\left(I_c(x_n) - I_c(x_{n,1}, x_{n,2} - 1)\right)$.
The Poisson equation (4) can be solved efficiently using discrete Fourier transform [28,31]. We follow [31] and briefly derive the necessary equations. The discrete, two-dimensional Fourier transform of the function $F_c$ is given as
$\hat{F}_{r,s} = \frac{1}{N} \sum_{u = 1}^H \sum_{v = 1}^W F_{u, =v} \exp\left(\frac{2\pi i r u}{H}\right) \exp\left(\frac{2\pi s v}{W}\right)$(5),
while the inverse, discrete, two-dimensional Fourier transform of the image channel $I_c$ can be written as
$I_{u,v} = \frac{1}{N} \sum_{r = 1}^H \sum_{s = 1}^W \hat{I}_{r,s} \exp\left(\frac{-2\pi i u r}{H}\right) \exp\left(\frac{-2\pi v s}{W}\right)$(6).
Transforming both sides of equation (4) by the discrete, two-dimensional Fourier transform yields the following relationship:
$\hat{I}_{r,s} = \frac{\hat{F}_{r,s}}{2\left(\cos\left(\frac{2\pi r}{H}\right) + \cos\left(\frac{2\pi s}{W}\right) - 2\right)}$.
Applying the inverse, discrete, two-dimensional Fourier transform to retrieve $I_c$ solves the Poisson equation (4) in the case of periodic boundary conditions. However, replacing equations (5) and (6) with the discrete, two-dimensional cosine transform, see [31], serves the constraints of Neumann boundary conditions as in equation (4).
Generalization to Video
The Retinex algorithm as implemented by Morelet al. [28] can easily be generalized to video. The Poisson equation, as formualted for the image $I$ in equation (4), equally holds for the video $V$ and equations (5) and (6) may easily be generalized to three dimensions. Only the right hand side $F_c(x_n)$, $X_n \in \underline{H} \times \underline{W} \times \underline{T}$, of equation (4) needs to be adapted as follows:
$F_c(x_n) = \lambda\left(I_c(x_n) - I_c(x_{n,1} + 1, x_{n,2}, x_{n,3})\right) + \lambda\left(I_c(x_n) - I_c(x_{n,1} - 1, x_{n,2}, x_{n,3})\right)$
$+ \lambda\left(I_c(x_n) - I_c(x_{n,1}, x_{n,2} + 1, x_{n,3})\right) + \lambda\left(I_c(x_n) - I_c(x_{n,1}, x_{n,2} - 1, x_{n,3})\right)$
$+ \lambda\left(I_c(x_n) - I_c(x_{n,1}, x_{n,2}, x_{n,3} + 1)\right) + \lambda\left(I_c(x_n) - I_c(x_{n,1}, x_{n,2}, x_{n,3} - 1)\right)$.
Implementation
An implementation is provided by Limare et al. [32], available on GitHub, and uses FFTW3 [33] to compute the discrete cosine transform in two or three dimensions. Each image channel $I_c$ is processed independently. An OpenCV [34] wrapper can also be found on GitHub.
The main limitation when generalizing to video is the temporal segmentation needed due to memory limitations. However, the algorithm can be applied on short, overlapping subsequences which are fused afterwards. In the best case, these overlapping regions could be encoded as constant boundary condition for the Poisson equation (4).
Results
Figure 2 shows the influence of the threshold $\tau$ on two images, one taken from the dataset by Bell et al. [7] and another one taken from the dataset by Beigpour et al. [29]. Further, figure 3 compares the Retinex algorithm to the approach by Bell et al. [7], available on GitHub. Note that shading can, theoretically, not be recovered without knowing illumination. However, Bell et al. [7] assume white illumination to approximate shading and their algorithm, therefore, also returns shading which is excluded for comparison.



















Discussion
The Retinex algorithm can be seen as the first approach to intrinsic images. Therefore, as seen in figure 3, the results are not comparable to state-of-the-art approaches as for example provided by Bell et al. [7]. However, the assumptions made by the Retinex theory, in particular smooth shading and piece-wise constant reflectance, are still used in many recent approaches. State-of-the-art approaches even add additional assumptions as for example sparsity of reflectance [9,13] or use additional information as for example depth [10,21] or video [21,25]. Overall, the problem is inherently global such that local decisions as made by the Retinex algorithm give poor results. It would be interesting to investigate whether the global problem, especially regarding complex scenes, can be decomposed into simpler local problems which are easier to solve. Further, for several applications, we need to ask whether true reflectance is actually necessary to improve performance of subsequent tasks. For example in image segmentation, reflectance and shading provided by a state-of-the-art algorithm can also be seen as additional feature without the requirement of begin true reflectance and shading.
- [1] E. H. Land and J. J. McCann. Lightness and retinex theory. Journal of the Optical Society of America, 61(1):1-11, January 1971.
- [2] E. H. Land. Recent advances in retinex theory and some implications for cortical computations: Color vision and natural images. In National Academy of Sciences of the United States of America, volume 80, pages 5163-5169, August 1983.
- [3] B. K. P. Horn. Determining lightness from an image. Computer Graphics and Image Processing, 3(4):277-299, December 1974.
- [4] H. G. Barrow and J. M. Tenenbaum. Recovering intrinsic scene characteristics from images. Academic Press, New York, NY, 1978.
- [5] A. Blake. Boundary conditions for lightness computation in mondrian world. Computer Vision, Graphics, and Image Processing, 32(3):314-327, 1985.
- [6] N. Banic and S. Loncaric. Light random sprays retinex: Exploiting the noisy illumination estimation. IEEE Signal Processing Letters, 20(12):1240-1243, 2013.
- [7] S. Bell, K. Bala, and N. Snavely. Intrinsic images in the wild. Graphics, ACM Transactions on, 33(4):159, 2014.
- [8] R. B. Grosse, M. K. Johnson, E. H. Adelson, and W. T. Freeman. Ground truth dataset and baseline evaluations for intrinsic image algorithms. In Computer Vision, International Conference on, pages 2335-2342, Kyoto, Japan, September 2009.
- [9] P. V. Gehler, C. Rother, M. Kiefel, L. Zhang, and B. Schölkopf. Recovering intrinsic images with a global sparsity prior on reflectance. In Advances in Neural Information Processing Systems, pages 765-773, Granada, Spain, December 2011.
- [10] Q. Chen and V. Koltun. A simple model for intrinsic image decomposition with depth cues. In Computer Vision, International Conference on, Sydney, Australia, December 2013.
- [11] Y. Li and M. S. Brown. Single image layer separation using relative smoothness. In Computer Vision and Pattern Recognition, Conference on, pages 2752-2759, Columbus, OH, June 2014.
- [12] M. F. Tappen, W. T. Freeman, and E. H. Adelson. Recovering intrinsic images from a single image. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 27(9):1459-1472, September 2005.
- [13] I. Omer and M. Werman. Color lines: Image speci c color representation. In Computer Vision and Pattern Recognition, Conference on, pages 946-953, Washington, DC, June 2004.
- [14] J. T. Barron and J. Malik. High-frequency shape and albedo from shading using natural image statistics. In Conference on Computer Vision and Pattern Recognition, Conference on, pages 2521-2528, Colorado Springs, CO, June 2011.
- [15] J. T. Barron and J. Malik. Color constancy, intrinsic images, and shape estimation. In Computer Vision, European Conference on, volume 7575 of Lecture Notes in Computer Science, pages 57-70, Florence, Italy, October 2012. Spriner.
- [16] J. T. Barron and J. Malik. Shape, albedo, and illumination from a single image of an unknown object. In Computer Vision and Pattern Recognition, Conference on, pages 334-341, Providence, RI, June 2012.
- [17] J. T. Barron and J. Malik. Intrinsic scene properties from a single RGB-D image. In Computer Vision and Pattern Recognition, Conference on, pages 17-24, Portland, OR, June 2013.
- [18] J. T. Barron and J. Malik. Shape, illumination, and reflectance from shading. Technical Report UCB/EECS-2013-117, Electrical Engineering and Computer Sciene Department, University of California, Berkeley, May 2013.
- [19] E. Garces, A. Munoz, J. Lopez-Moreno, and D. Gutierrez. Intrinsic images by clustering. Computer Graphics Forum, 31(4):1415-1424, 2012.
- [20] L. Shen, C. Yeo, and B.-S. Hua. Intrinsic image decomposition using a sparse representation of reflectance. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 35(12):2904-2915, 2013.
- [21] K. Joon Lee, Q. Zhao, X. Tong, M. Gong, S. Izadi, S. U. Lee, P. Tan, and S. Lin. Estimation of intrinsic image sequences from image+depth video. In Computer Vision, European Conference on, volume 7577 of Lecture Notes in Computer Science, pages 327-340. Springer, 2012.
- [22] Y. Weiss. Deriving intrinsic images from image sequences. In Computer Vision, International Conference on, pages 68-75, Vancouver, Canada, July 2001.
- [23] P.-Y. Laff ont, A. Bousseau, S. Paris, F. Durand, and G. Drettakis. Coherent intrinsic images from photo collections. Graphics, ACM Transactions on, 31(6):202, 2012.
- [24] Y. Matsushita, S. Lin, S. B. Kang, and H.-Y. Shum. Estimating intrinsic images from image sequences with biased illumination. In Computer Vision, European Conference on, volume 3022 of Lecture Notes in Computer Science, Prague, Czech Republic, May 2004. Springer.
- [25] N. Kong, P. V. Gehler, and M. J. Black. Intrinsic video. In Computer Vision, European Conference on, volume 8690 of Lecture Notes in Computer Science, pages 360-375. Springer, 2014.
- [26] G. Ye, E. Garces, Y. Liu, Q. Dai, and D. Gutierrez. Intrinsic video and applications. Graphics, ACM Transactions on, 33(4):80, 2014.
- [27] N. Bonneel, K. Sunkavalli, J. Tompkin, D. Sun, S. Paris, and H. P ster. Interactive intrinsic video editing. Graphics, ACM Transactions on, 33(6):197:1-197:10, 2014.
- [28] J.-M. Morel, A. B. Petro, and C. Sbert. A PDE formalization of retinex theory. Image Processing, IEEE Transactions on, 19(11):2825-2837, November 2010.
- [29] S. Beigpour, M. Serra, J. van de Weijer, R. Benavente, M. Vanrell, O. Penacchio, and D. Samaras. Intrinsic image evaluation on synthetic complex scenes. In Image Processing, International Conference on, pages 285-289, Melbourne Australia, September 2013.
- [30] D. J. Butler, J. Wul , G. B. Stanley, and M. J. Black. A naturalistic open source movie for optical flow evaluation. In Computer Vision, Conference on, volume 7577 of Lecture Notes in Computer Science, pages 611-625. Springer, October 2012.
- [31] W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery. Numerical Recipes 3rd Edition: The Art of Scienti c Computing. Cambridge University Press, New York, NY, 3 edition, 2007.
- [32] N. Limare, A. B. Petro, C. Sbert, and Jean-Michel Morel. Retinex poisson equation: a model for color perception. Image Processing On Line, 1, 2011.
- [33] M. Frigo and S. G. Johnson. The design and implementation of ff tw3. Proceedings of the IEEE, 93(2):216{231, February 2005.
- [34] G. Bradski. The OpenCV Library. Dr. Dobb's Journal of Software Tools, 2000. http://opencv.org/