Also see the master thesis proposal. More details, including follow-up work, code and data can also be found on the project page.
The LaTeX source of the thesis is now available on GitHub: davidstutz/master-thesis-shape-completion.
Introduction
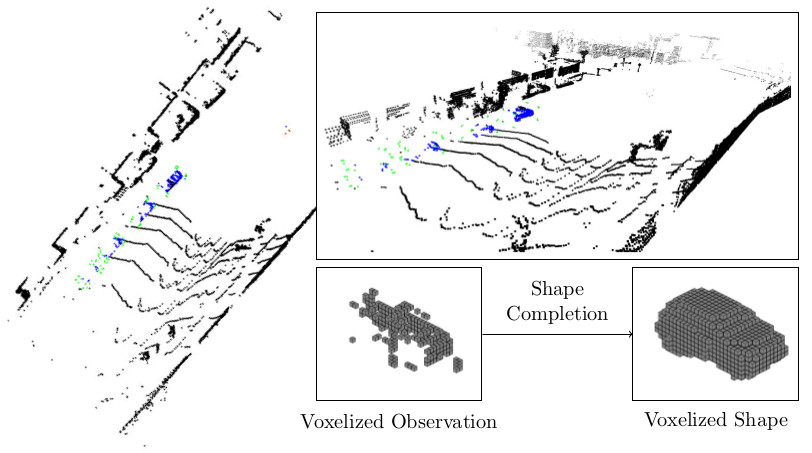
Figure 1 (click to enlarge): Illustration of the shape completion problem on KITTI.
Shape perception is a long-standing and fundamental problem both in human [][] and computer vision []. In both disciplines, a large body of work focuses on 3D reconstruction:reconstructing objects or scenes from one or more views, an inherently ill-posed inverse problem because many configurations of shape, color, texture and lighting may give rise to the very same views []. In human vision, one of the fundamental problems is understanding how the human visual system accomplishes such tasks; in computer vision, in contrast, the goal is to develop 3D reconstruction systems. Results from human vision suggest that priors as well as the ability to process involved cues is innate and not learned. In computer vision, as well, cues and priors are commonly built into 3D reconstruction pipelines through explicit assumptions. Recently, however, researchers started to learn shape models from data. Predominantly generative models have been used to learn how to generate, manipulate and reason about shapes [][][][][][]. Learning such shape models offers many interesting possibilities for a wide variety of problems in 3D computer vision.
In this context, we focus on a specific problem in the realm of 3D reconstruction, namely shape completion from point clouds, as illustrated in Figure 1. This problem occurs when only a single view of an individual object is provided and large parts of the object are not observed or occluded. Motivated by the success of learning shape models, we intend to tackle shape completion using a learning-based approach where we make use of shape priors learned from large datasets of shapes such as ModelNet [] or ShapeNet []. This idea, i.e. learning-based shape completion, has recently gained traction by works such as [][][][][] or []. Most learning-based approaches require full supervision; this means that observations are either synthesized from known models, or datasets need to be annotated. On real data, e.g. on KITTI [][], shape completion without supervision can be posed as energy minimization problem over a latent space of shapes [][][]. In this case, shape completion usually involves solving a complex minimization problem using iterative approaches. Deep learning-based approaches, in contrast, can complete shapes using a single forward pass of the learned network. We find that both problems, the required supervision on the one hand and the computationally expensive optimization problems at the other, constrain the applicability of these approaches to real data considerably.
Contributions
We propose two different probabilistic frameworks enabling us to learn shape completion with weak supervision, thereby mitigating both mentioned problems. In both cases, we first train a shape prior, particularly a variational auto-encoder. In the spirit of [], we can then formulate shape completion as maximum likelihood problem over the learned latent space. Instead of maximizing the likelihood independently for distinct observations, however, we follow the idea of amortized inference [] and learn to predict the maximum likelihood solution directly given the corresponding observations. Specifically, we train an encoder, which embeds the observations in the same latent space, using an unsupervised, maximum likelihood loss between the observations and the corresponding shapes. This variant of amortized maximum likelihood allows us to learn shape completion under real conditions,e.g. on KITTI, and is able to compete with a fully-supervised baseline on a ShapeNet-based, synthetic dataset used for evaluation.
As alternative approach, we extend the general framework of latent space models, as implemented by variational auto-encoders, to specifically account for the observations. Applied to a pre-trained variational auto-encoder — representing the required shape prior — we derive the evidence lower bound of this extended variational auto-encoder which we then optimize in an unsupervised fashion, i.e. only given the observations. We also show that the underlying objective is closely related to our amortized maximum likelihood approach. On our synthetic, ShapeNet-based dataset, we experimentally demonstrate the applicability of the extended variational auto-encoder regarding shape completion. Overall, we present two approaches in favor of our claim that shape priors allow to learn shape completion in an unsupervised fashion, thereby also introducing many interesting directions for future research.
Download
The thesis can be downloaded below:
Loading the document may take some time ...
Thesis (∼ 26.7MB)Slides (∼ 10.8MB)
Please cite the thesis as follows:
@misc{Stutz:2017,
author = {David Stutz},
title = {Learning Shape Completion from Bounding Boxes with CAD Shape Priors},
month = {September},
year = {2017},
institution = {RWTH Aachen University},
address = {Aachen, Germany},
howpublished = {http://davidstutz.de/},
}
Table of Contents
shape-completion-thesis2017-tocReferences
- [] Z. Pizlo. Human perception of 3d shapes. In International Conference on Computer Analysis of Images and Patterns, pages 1–12, 2007.
- [] Z. Pizlo. 3D shape: Its unique place in visual perception. MIT Press, 2010.
- [] Y. Furukawa and C. Hern ́andez. Multi-view stereo: A tutorial. Foundations and Trends in Computer Graphics and Vision, 9(1-2):1–148, 2015.
- [] R. Girdhar, D. F. Fouhey, M. Rodriguez, and A.hinav Gupta. Learning a predictable and generative vector representation for objects. In European Conference on Computer Vision, pages 484–499, 2016.
- [] A. Dai, C. R. Qi, and M. Nießner. Shape completion using 3d-encoder-predictor cnns and shape synthesis. CoRR, abs/1612.00101, 2016.
- [] A. Sharma, O. Grau, and M. Fritz. Vconv-dae: Deep volumetric shape learning without object labels. In European Conference on Computer Vision Workshops, pages 236–250, 2016.
- [] A. Brock, T. Lim, J. M. Ritchie, and N. Weston. Generative and discriminative voxel modeling with convolutional neural networks. CoRR, abs/1608.04236, 2016.
- [] Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3D ShapeNets: A deep representation for volumetric shapes. In IEEE Conference on Computer Vision and Pattern Recognition, pages 1912–1920, 2015.
- [] J. Wu, C. Zhang, T. Xue, B. Freeman, and J. Tenenbaum. Learning a probabilistic latent space of object shapes via 3d generative adversarial modeling. In Advances in Neural Information Processing Systems, pages 82–90, 2016.
- [] A. X. Chang, T. A. Funkhouser, L. J. Guibas, P. Hanrahan, Q.-X. Huang, Z. Li, S. Savarese, M. Savva, S. Song, H. Su, J. Xiao, L. Yi, and F. Yu. Shapenet: An information-rich 3d model repository. CoRR, abs/1512.03012, 2015.
- [] G. Riegler, A. O. Ulusoy, H. Bischof, and A. Geiger. Octnetfusion: Learning depth fusion from data. CoRR, abs/1704.01047, 2017.
- [] E. Smith and D. Meger. Improved adversarial systems for 3d object generation and reconstruction. CoRR, abs/1707.09557, 2017.
- [] H. Fan, H. Su, and L. J. Guibas. A point set generation network for 3d object reconstruction from a single image. CoRR, abs/1612.00603, 2016.
- [] D. J. Rezende, S. M. Ali Eslami, S. Mohamed, P. Battaglia, M. Jaderberg, and N. Heess. Unsupervised learning of 3d structure from images. In Advances in Neural Information Processing Systems, pages 4997–5005, 2016.
- [] V. A. Prisacariu, A. V. Segal, and I. D. Reid. Simultaneous monocular 2d segmentation, 3d pose recovery and 3d reconstruction. In Asian Conference on Computer Vision, pages 593–606, 2012.
- [] S. Dambreville, R. Sandhu, A. J. Yezzi, and A. Tannenbaum. Robust 3d pose estimation and efficient 2d region-based segmentation from a 3d shape prior. In European Conference on Computer Vision, pages 169–182, 2008.
- [] R. Sandhu, S. Dambreville, A. J. Yezzi, and A. Tannenbaum. Nonrigid 2d-3d pose estimation and 2d image segmentation. In IEEE Conference on Computer Vision and Pattern Recognition, pages 786–793, 2009.
- [] M. Menze, C. Heipke, and A. Geiger. Joint 3d estimation of vehicles and scene flow. In ISPRS Workshop on Image Sequence Analysis, pages 3061–3070, 2015.
- [] L. Ma and G. Sibley. Unsupervised dense object discovery, detection, tracking and reconstruction. In Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part II, pages 80–95, 2014.
- [] M. J. Leotta and J. L. Mundy. Predicting high resolution image edges with a generic, adaptive, 3-d vehicle model. In IEEE Conference on Computer Vision and Pattern Recognition, pages 1311–1318, 2009.
- [] F. Güney and A. Geiger. Displets: Resolving stereo ambiguities using object knowledge. In IEEE Conference on Computer Vision and Pattern Recognition, pages 4165–4175, 2015.
- [] A. Dame, V. A. Prisacariu, C. Y. Ren, and I. D. Reid. Dense reconstruction using 3d object shape priors. In IEEE Conference on Computer Vision and Pattern Recognition, pages 1288–1295, 2013.
- [] S. Y.-Z. Bao, M. Chandraker, Y. Lin, and S. Savarese. Dense object reconstruction with semantic priors. In IEEE Conference on Computer Vision and Pattern Recognition, pages 1264–1271, 2013.
- [] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the KITTI vision benchmark suite. In IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361, 2012.
- [] A. Geiger, P. Lenz, C. Stiller, and R. Urtasun. Vision meets robotics: The KITTI dataset. International Journal of Robotics Research, 32(11):1231–1237, 2013.
- [] F. Engelmann, J. Stückler, and B. Leibe. Joint object pose estimation and shape reconstruction in urban street scenes using 3d shape priors. In German Conference on Pattern Recognition, pages 219–230, 2016.
- [] D. P. Kingma and M. Welling. Auto-encoding variational bayes. CoRR, abs/1312.6114, 2013.
- [] S. Gershman and N. D. Goodman. Amortized inference in probabilistic reasoning. In Conference of the Cognitive Science Society, 2014.