Content-based image or object retrieval, the problem of finding images within a large database containing the same or similar objects or scenes as a given query image, is a fundamental problem in computer vision. In particular, in order to extract useful information from large databases of images these databases need to be organized and searchable.
While the problem has been studied for several decades, recent success is based on the Bag of Visual Words model proposed by Sivic and Zisserman [2]. Local descriptors, used to characterize interest points within the image, are quantized into so-called visual words and the image is represented by the corresponding word counts. While the Bag of Visual Words model has steadily been improved (for example [3, 1, 4]), different techniques of aggregating local descriptors (for example [5, 6, 7, 8]) have been used.
Problem
Given a database of images $X = \{x_1,...,x_N\}$ and a query image $z_0$ showing a particular object or scene, the task of image retrieval is usually formalized as follows:
Problem. Find an ordered list of images $Z = (z_1,\ldots,z_K)$ such that, for an appropriate distance function $d$, it holds:
$d(z_0,z_k) \leq d(z_0, z_{k + 1}), 1 \leq k \leq K\quad\text{and}\quad d(z_0,z_k) < d(z_0,x_n)\forall 1 \leq k \leq K, x_n \notin Z$
which basically describes a $K$-nearest neighbor search.
While early work on image retrieval presented complete retrieval systems, recent publications usually focus on subproblems. Therefore, in the following, we roughly divide this problem into image description, compression, nearest neighbor search and query expansion.
Image Description
Aggregation of local descriptors Local descriptors are designed to represent regions around interest points. For image retrieval, these interest points are computed using a scale, rotation and affine invariant detector. Details can be found in [10]. Most interest point detectors are based on early work by Harris and Stephens:
The "Harris"-detector (note that a more recent description can also be found in [1]) is based on the second moment matrix $A$ of an image $x_n$. The corresponding eigenvalues $\lambda_1, \lambda_2$ represent the signal change in two orthogonal directions and interest points are extracted at pixels where both eigenvalues are large. For efficiency, Harris and Stephens propose to maximize
$\lambda_1\lambda_2 - \kappa(\lambda_1 + \lambda_2)^2 = \text{det}(A) - \kappa \text{trace}(A)^2$ with $A = \begin{pmatrix}\partial_x^2 x_n & \partial_{xy} x_n\\\partial_{xy} x_n & \partial_y^2 x_n\end{pmatrix}$
where $\kappa$ is a sensitivity parameter. In practice the detector is applied in scale space, that is on a set of images
$x_n^{(\sigma_s)} = g_{\sigma_s} \ast x_n$
where $\ast$ denotes convolution and $g_{\sigma_s}$ is a Gaussian kernel with standard deviation $\sigma_s$ with $\sigma_s$ sampled at logarithmic scale. Therefore, it automatically selects the optimal scale and defines the size of the region used for local descriptors. Several extensions - for example the Harris-Laplace Detector - have been proposed, see [1].
- [1] Krystian Mikolajczyk and Cordelia Schmid. Scale and affine invariant interest point detectors. International Journal of Computer Vision, 60(1):63–86, October 2004.
The most popular interest point descriptor is SIFT [11]. However, many other descriptors have been proposed and used. Another example is given by the Sparse-Coded Micro Feature [6].
In 2004, Lowe introduces to most popular interest point descriptor to date -- Scale Invariant Feature Transform (SIFT). While there are several implementations available (OpenCV's implementation, VLFeat's implementation, Vedaldi's implementation ...), Lowe holds a US patent for SIFT meaning that SIFT is often not applicable in practice. The following is an informal description of SIFT.
First, given a specific scale, the orientation of the interest point is determined by computing a gradient orientation histogram under a Gaussian window and using the maximum bin as orientation. In practice, $36$ bins are used to determine the orientation and up to three orientations corresponding to bins above 80% of the maximum bin are retained as additional orientations. Then, SIFT divides a rectangular region, rotated according to the orientation determined previously, around the interest point into a $4 \times 4$ grid. For each grid element, a 8-bin gradient orientation histogram is computed using trilinear interpolation. Pixels are weighted according to gradient magnitude and a Gaussian window. This results in a $c = 4\cdot 4\cdot 8$-dimensional descriptors which is $L_2$-normalized.
In image retrieval, for example, SIFT is the most commonly used local descriptor and several aggregation techniques are tailored specificly to SIFT descriptors (for example [1]). Nevertheless, several extensions have been proposed, especially concerning normalization. For example, Arandjelovic and Zisserman [2] ´ propose to use RootSIFT, that is the original SIFT descriptor is L1-normalized and the individual elements are square-rooted. As result, the Euclidean distance on RootSIFT resembles the Bhattacharyya coefficient of the original SIFT descriptors.
- [1] H. Jégou, M. Douze, C. Schmid, P. Pérez. Aggregating local descriptors into a compact image representation. In Computer Vision and Pattern Recognition, Conference on, pages 3304–3311, San Fransisco, California, June 2010.
- [2] R. Arandjelovic, A. Zisserman. Three things everyone should know to improve object retrieval. In Computer Vision and Pattern Recognition, Conference on, pages 2911–2918, Providence, Rhode Island, June 2012.
A key element in image retrieval research is concerned with the aggregation of these local descriptors into an image representation of fixed size. The following publications represent several popular approaches to this problem and have been adapted and used in many different ways.
Sivic and Zisserman, motivated by early text-retrieval systems, present the so-called bag of visual words model for image retrieval. First, they cluster all local descriptors, denoted by $Y = \bigcup_{n = 1}^N Y_n$ where $Y_n$ are the local descriptors extracted from image $n$ (out of $N$ images), using $k$-means clustering to define a vocabulary of visual words. Subsequently, descriptors are assigned to the nearest visual word and the global image representation is a sparse vector of word counts. Let $\hat{Y} = \{\hat{y}_1,\ldots,\hat{y}_M\}$ be the extracted visual words, then each extracted descriptor $y_{l,n} \in Y_n$ is represented by a vector (the so-called embedding):
$f(y_{l,n}) = \left(\delta(NN_{\hat{Y}}(y_{l,n}) = \hat{y}_1),\ldots,\delta(NN_{\hat{Y}}(y_{l,n}) = \hat{y}_M)\right)$
where $NN_{\hat{Y}}(y_{l,n})$ denotes the nearest neighbor of $y_{l,n}$ (the $l$-th extracted descriptor in image $n$) in $\hat{Y}$. Therefore, $f_m(y_{l,n}) = 1$ if and only if $NN_{\hat{Y}}(y_{l,n}) = \hat{y}_m$. These embeddings are then aggregated in a single vector of word counts:
$F(Y_n) = \sum_{l = 1}^L f(y_{l,n})$
In practice, however, the so-called term-frequency inverse-document-frequency weighting is applied:
$F_m(Y_n) = \frac{\sum_{l = 1}^L f_m(y_{l,n})}{\sum_{m' = 1}^M \sum_{l = 1}^L f_{m'}(y_{l,n})} log\left(\frac{N}{\sum_{n = 1}^N \sum_{l = 1}^L f_m(y_{l,n})}\right)$
where $f_m(y_{l,n})$ and $F_m(Y_n)$ denote component $m$ of the corresponding vectors. The first term is the fraction of local descriptors assigned to visual word $\hat{y}_m$ and, thus, determines the importance of $\hat{y}_m$. In contrast, the second term down-weights the influence of local descriptors assigned to word $\hat{y}_m$ if it occurs frequently in the whole database.
Perronnin and Dance use Fisher Vectors [1] for image categorization. However, the approach is often used for image retrieval, as for example in [2]. Fisher vectors area easily motivated when considering a Gaussian mixture model for the extracted descriptor $y_{l,n}$ in image $n$:
$p(y_{l,n}) = \sum_{m = 1}^M w_m \mathcal{N}(y_{l,n}|\mu_m, \Sigma_m)$, $\sum_{m = 1}^M w_m = 1$
where $\mathcal{N}(y_{l,n}|\mu_m, \Sigma_m)$ denotes a Gaussian with mean $\mu_m$ and covariance $\Sigma_m$. The model is learned on $Y = \bigcup_{n = 1}^N Y_n$, the set of all local descriptors extracted from the images $n = 1,\ldots,N$, using the Expectation Maximization algorithm. The idea of Fisher vectors is to characterize a local descriptor $y_{l,n}$ by the following gradient:
$\nabla_{\mu_m} \log(p(y_{l,n}))$.
intuitively, this characterizes each descriptor by the direction in which the descriptor should be adapted to better fit the Gaussian model. Taking into account all local descriptors $Y_n$ of image $n$, which are assumed to be independent, the log-likelihood can be written as
$\log(p(Y_n)) = \sum_{l = 1}^L \log(p(y_{l,n}))$.
The partial derivative of the log-likelihood with respect to the mean $\mu_m$ is given as
$\sum_{l = 1}^L \gamma_m(y_{l,n}) \Sigma_m^{-1}(y_{l,n} - \mu_m)$, $\gamma_m(y_{l,n}) = \frac{w_m \mathcal{N}(y_{l,n}|\mu_m,\Sigma_m)}{\sum_{m' = 1}^M w_{m'} N(y_{l,n}|\mu_{m'},\Sigma_{m'})}$
In practice, the covariance $\Sigma_m$ is asumed to be diagonal, that is $\Sigma_m = diag(\sigma_{1,m}^2,\ldots,\sigma_{c,m}^2)$ where $c$ is the dimensionality of the descriptors. Further, the gradient vectors are normalized using the Fisher information matrix
$Z = \mathbb{E}_{Y_n}[\nabla \log(p(Y_n))\nabla \log(p(Y_n))^T]$
for which Perronnin et al. derive the following approximation:
$Z_{\mu_m}^{-1}\nabla_{\mu_m} \log(p(y_{l,n}))$ with $Z_{\mu_m} = \frac{Lw_m}{\sigma_m^2}$
where the inversion as well as the division is meant element-wise. Based on the above derivation, each descriptor is embedded as
$f(y_{l,n}) = \left(Z_{\mu_1}^{-1}\nabla_{\mu_1} p(y_{l,n}),\ldots,Z_{\mu_M}^{-1}\nabla_{\mu_M} p(y_{l,n})\right)$.
These vectors are then aggregate by summing over all $f(y_{l,n})$ for a specific image $n$. The result is usually power-law normalized.- [1] T. S. Jaakkola, D.Haussler. Exploiting generative models in discriminative classifiers. In Advances in Neural Information Processing Systems, pages 487–493, Denver, Colorado, November 1999.
- [2] A. Gordo, J. A. Rodríguez-Serrano, F. Perronnin, E. Valveny. Leveraging category-level labels for instance-level image retrieval. In Computer Vision and Pattern Recognition, Conference on, pages 3045–3052, Providence, Rhode Island, June 2012.
Similar to the Bag of Visual Words model [1], Jégou et al. approach the problem of image retrieval by first computing a vocabulary $M$ of visual words learned using $k$-means clustering. Instead of counting word occurrences, they consider the corresponding residuals:
$f(y_{l,n}) = (\delta(NN_{\hat{Y}}(y_{l,n}) = \hat{y}_1)(y_{l,n} - \hat{y}_1), \ldots, \delta(NN_{\hat{Y}}(y_{l,n}) = \hat{y}_M)(y_{l,n} - \hat{y}_M))$
where $\hat{Y}= \{\hat{y}_1, \ldots, \hat{y}_M\}$ is the set of learned visual words and $y_{l,n}$ is the $l$-th feature extracted from image $n$. These so-called embeddings are then aggregated using
$F(Y_n) = \sum_{l = 1}^L f(y_{l,n})$.
The image representation $F(Y_n)$ is usually $L_2$-normalized.
- [1] J. Sivic, A. Zisserman. Video google: A text retrieval approach to object matching in videos. In Computer Vision, International Conference on, pages 1470–1477, Nice, France, October 2003.
Ge et al. propose a sparse-coding approach to image retrieval. Similar to other approaches (e.g. [1]), they compute a vocabulary of visual words $\hat{Y} = \{\hat{y}_1,\ldots,\hat{y}_M\}$ from the extracted descriptors of all $N$ images $Y = \bigcup_{n = 1}^N Y_n$ and apply sparse coding as embedding:
$f(y_{l,n}) = \text{arg}\min_{r_l} \|y_{l,n} - \hat{Y} r_l\|_2^2 + \lambda \|r_l\|_1$.
where $\lambda$ is a regularization parameter and $r_l$ is the sparse code computed for descriptor $y_{l,n}$. As second step, these sparse codes are pooled into a single $M$-dimensional feature vector. Max pooling is given by
$F(Y_n) = \left(\max_{1\leq l \leq L}\{f_1(y_{l,n})\},\ldots,\max_{1\leq l \leq L}\{f_M(y_{l,n})\}\right)$
where $f_m(y_{l,n})$ refers to the $m$-th components of $f(y_{l,n})$. The final image representation is $L_2$-normalized.
- [1] J. Sivic, A. Zisserman. Video google: A text retrieval approach to object matching in videos. In Computer Vision, International Conference on, pages 1470–1477, Nice, France, October 2003.
Jégou and Zisserman consider an image retrieval system similar to the Bag of Visual Words model [1] where local descriptors $y_{l,n}$ computed on images $x_n$, $n = 1,\ldots,N$, are quantized into visual words $\hat{Y} = \{\hat{y}_1,\ldots,\hat{y}_M\}$ (e.g. uisng $k$-means) and each image is described by
$F(Y_n) = \sum_{l = 1}^L f(y_{l,n})$ with $f(y_{l,n}) \in \mathbb{R}^M$, $f_m(y_{l,n}) = 1 \Leftrightarrow \hat{y}_m = NN_{\hat{Y}}(y_{l,n})$.
Here, $Y_n$ is the set of local descriptors for image $x_n$ and $NN_{\hat{Y}}(y_{l,n})$ represents the nearest neighbor of local descriptor $y_{l,n}$ in $\hat{Y}$.
Jégou and Zisserman note that the above aggregation function $F(Y_n)$ gives unequal weights to the different local descriptors $y_{l,n} \in Y_n$. Therefore, they consider the contribution of a single descriptor $y_{l,n}$ to the set similarity
$F(Y_n)^T F(Y_n) = \sum_{l = 1}^L \sum_{l' = 1}^L f(y_{l,n})^T f(y_{l',n})$(1)
which can be written as
$f(y_{l,n})^T \sum_{l' = 1}^L f(y_{l',n}) = \|f(y_{l,n})\|_2^2 + f(y_{l,n})^T \sum_{l \neq l'} f(y_{l',n})$.
To let each local descriptor $y_{l,n}$ contribute equally to Equation (1), Jégou and Zisserman first compute the residuals
$r_{l,m} = \frac{y_{l,n} - \hat{y}_m}{\|y_{l,n} - \hat{y}_m\|_2}$
for each local descriptor $y_{l,n}$. These residuals only contain directional information (e.g. in contrast to VLAD [2] where unnormalized residuals are used). With $r_l = (r_{l,1}^T,\ldots,r_{l,M}^T)$, the local descriptor $y_{l,n}$ is then embedded using
$f(y_{l,n}) = \Sigma(r_l)^\frac{1}{2}(r_k - \mu(r_l))$.
$\Sigma(r_l)$ and $\mu(r_l)$ are covariance and mean estimated on all $r_l$ (i.e. across all local descriptors $y_{l,n}$ for all images $n = 1,\ldots,N$). Furthermore, Jégou and Zisserman propose the concept of a democratic kernel: a kernel $k(y_{l,n}, y_{l',n})$ is called democratic if there exists a constant $\kappa$ such that
$\sum_{l' = 1}^L k(y_{l,n}, y_{l',n}) = \kappa$ $\forall 1 \leq l \leq L$.
Such a kernel can efficiently be learned using an adapted Sinkhorn algorithm [3] when considering a weighted kernel
$k'(y_{l,n}, y_{l',n}) = \lambda_l \lambda_{l'} k(y_{l,n}, y_{l',n}) = \lambda_l \lambda_{l'} y_{l,n}^Ty_{l',n}$
and solving the system of equations given by
$\lambda_l\left(\sum_{l' = 1}^L \lambda_{l'} k(y_{l,n}, y_{l',n})\right) = \kappa$ with $\lambda_{l} > 0$, $\forall 1 \leq l \leq L$.
The embeddings $f(y_{l,n})$ are then aggregated using the weighted sum
$F(Y_n) = \sum_{l = 1}^L \lambda_l f(y_{l,n})$.
- [1] J. Sivic, A. Zisserman. Video google: A text retrieval approach to object matching in videos. In Computer Vision, International Conference on, pages 1470–1477, Nice, France, October 2003.
- [2] H. Jégou, M. Douze, C. C. Schmid, P. Pérez. Aggregating local descriptors into a compact image representation. In Computer Vision and Pattern Recognition, Conference on, pages 3304–3311, San Fransisco, California, June 2010.
- [3] R. Sinkhorn. A relationship between arbitrary positive matrices and doubly stochastic matrices. Annals of Mathematical Statistics, 35(2):876-879, June 1964.
Philbin et al. try to avoid quantization errors usually incurred by image retrieval systems based on the Visual Bag of Words model [1] (where so-called visual words are computed by quantizing a set of local descriptors extracted from a set of images using $k$-means) by learning a linear transformation $P\in\mathbb{R}^{c' \times c}$ such that matching local descriptors lie more closely together while non-matching local descriptors lie farther apart. Here, $c$ is the dimension of the extracted local descriptors and $c'$ is the desired dimension of the transformed local descriptors. Given a dataset of images annotated as matching and non-matching image pairs, a dataset of local descriptor pairs is created as follows:
- Randomly select a pair of images, detect interest point and extract local descriptors;
- then, apply Lowe's second-nearest neighbor ratio test (local descriptors where the fraction of distances to the first and the second nearest-neighbor is above $0.8$ are discarded where the second-nearest neighbor is constrained to come from an unrelated image);
- and estimate an affine transformation using RANSAC.
The dataset consists of the inliers found by RANSAC as positives $Y_{\text{pos}} \subseteq \mathbb{R}^c \times \mathbb{R}^c$, the corresponding outliers as negatives $Y_{\text{out}}$ and random matches as "easy" negatives $Y_{\text{rnd}}$. Then, the transformation $P$ is learned by minimizing the following objective using stochastic gradient descent:
$E(P) = \sum_{(y_{l,n},y_{l',n}) \in Y_{\text{pos}}} \mathcal{L}(b_1 - d(Py_{l,n}, Py_{l',n})) + \sum_{(y_{l,n}, y_{l',n}) \in Y_{\text{out}}} \mathcal{L}(d(Py_{l,n}, Py_{l',n})-b_1)$
$+ \sum_{(y_{l,n}, y_{l',n}) \in Y_{\text{rnd}}} \mathcal{L}(d(Py_{l,n}, Py_{l',n}) - b_2) + \frac{\lambda}{2}\|P\|^2$(1)
where $d$ is a chosen distance function and $\mathcal{L}$ is the logistic loss:
$\mathcal{L}(z) = \log(1 + \exp(-z))$.
and $b_1$, $b_2$ are the parameters of the maximum margin approach described by Equation (1).
- [1] J. Sivic, A. Zisserman. Video google: A text retrieval approach to object matching in videos. In Computer Vision, International Conference on, pages 1470–1477, Nice, France, October 2003.
Global descriptors Global descriptors, as for example GIST [9], have also been used for image retrieval. Still, aggregating local descriptors as described above is dominating the image retrieval literature. However, with the rise of deep learning, a new kind of global descriptors may become interesting:
Babenko et al. apply convolutional neural networks to image retrieval. In particular, the architecture proposed by Krizhevsky et al. [1] (shown in Figure 1), has been used to compute features for image retrieval. They experimented with different layers, dimensionality reduction techniques (e.g. PCA and Large-Margin Dimensionality Reduction [2]), and both the pre-trained model and a refined model to demonstrate state-of-the-art performance on many image retrieval datasets.
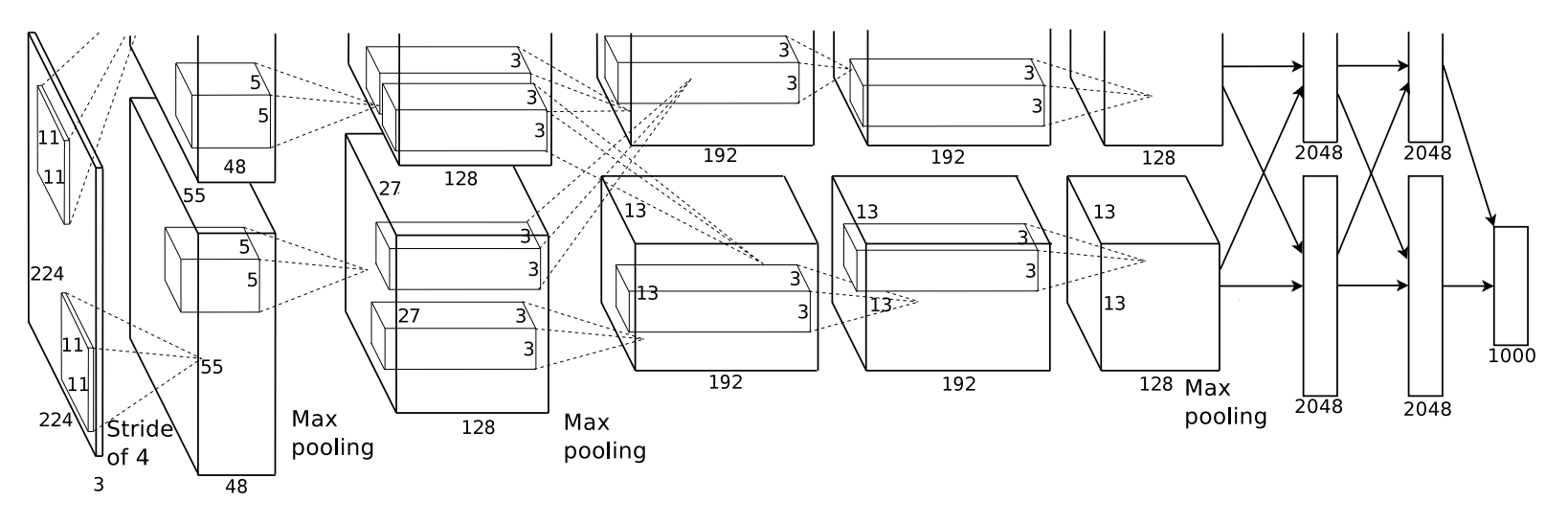
Figure 1 (click to enlarge): Architecture proposed in [1].
- [1] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, 2012.
- [2] K. Simonyan, O. M. Parkhi, A. Vedaldi, and A. Zisserman. Fisher vector faces in the wild. In British Machine Vision Conference, 2013.
Descriptor Compression
Given image representations $X = {x_1,...,x_N}$ of all images within the database, we are interested in the nearest neighbors of the query $z_0 \in X$ [12]. As this may be infeasible for large databases, authors often discuss compression of their proposed image representation. While PCA is frequently used within the image retrieval community (for example [14, 6, 15]), discriminative techniques may be beneficial. An example is the approach by Gordo et al. [13].
Gordo et al. propose an approach to dimensionality reduction of image representations for image retrieval. Given a training set of image representations extracted for image retrieval, they jointy learn a dimensionality reduction $P \in \mathbb{R}^{C' \times C}$ and a set of classifiers $w_t \in \mathbb{R}^{C'}, t \in \{1,\ldots,T\}$, in order to project the image representations and their labels into a common subspace. A large-margin framework is employed; the energy
$E(P) = \sum_{(x_n, t_n, t) : t \neq t_n} \max\{0, 1 - s(x_n, t_n) + s(x_n, t)\}$ with $s(x_n, t) = (P x_n)^T w_t$
is minimized using stochastic gradient descent. Here, $C$ is the dimension of the image representations and $C'$ the target dimensionality. For $n = 1,\ldots,N$, $(x_n, t_n)$ represents a pair of image representation and label from the training set. Then, $s(x_n, t)$ can be interpreted as the relevance of label $t$ to image representation $x_n$. During minimization, a triple $(x_n, t_n, t)$ with $t_n \neq t$ is sampled and the projection matrix $P$ as well as the classifiers $w_{t_n}$ and $w_t$ are updated only if the loss
$\max\{0, 1 - s(x_n,t_n) + s(x_n, t)\}$
is positive. Then, the update equations derived by Gordo et al. are as follows:
$P[\tau + 1] = P[\tau] + \gamma (w_{t_n}[\tau] - w_t[\tau])x_n^T$
$w_{t_n}[\tau + 1] = w_{t_n}[\tau] + \gamma P[\tau]x_n$
$w_t[\tau + 1] = w_t[\tau] - \gamma P[\tau] x_n$
where $\gamma$ is the learning rate and $\tau$ indexes the iterations. Finally, $P$ is used for dimensionality reduction while the classifiers $w_t$ are discarded.
Efficient Nearest-Neighbor Search
Even with compressed image representations, exhaustive nearest neighbor search may be inadequate. Jégou et al. [12] propose product quantization for approximate nearest neighbor search.
In image retrieval systems, nearest-neighbor search is used to retrieve relevant images corresponding to a specific query image. As feature spaces tend to be high-dimensional, Jégou et al. propose product quantization for approximate nearest-neighbor search. In general, a quantizer $q$ is a function mapping each image representation to one of $M$ centroids. Essentially, a quantizer tries to reconstruct a given database by $M$ representatives and, thus, the reconstruction error can be expressed as
$MSE(q) = \int p(x_n)d(x_n, q(x_n))^2 d x_n \approx \sum_{n = 1}^N d(x_n, q(x_n))^2$.(1)
Product quantization subdivides each image representation into subvectors and each subvector is quantized separately using $k$-means clustering. The advantage of the product quantization lies in reduced memory consumption. In particular, $k$-means clustering requires to store $\mathcal{O}(MC)$ floating point values, while product quantization stores $\mathcal{O}(QM^\ast C) = \mathcal{O}(M^{\frac{1}{Q}}C)$ with $Q$ being the number of quantizers and $M = (M^\ast)^Q$. Based on the above quantization, Jégou et al. propose two approaches to approximate search within the quantized image representations. Given a query image representation $z_0$, using symmetric distance computation, the distance $d(x_n, z_0)$ (e.g. Euclidean, Manhatten or similar) is approximated by
$d(x_n, z_0) \approx \hat{d}(x_n, z_0) = d(q(x_n), q(z_0))$
In contrast, asymmetric distance computation is given as
$\hat{d}(x_n, z_0) = d(x_n, q(z_0))$
Jégou et al. provide guarantees on the error of these approximations: the distance error of symmetric distance computation is statistically bounded by $MSE(q)$, while the distance error of asymmetric distance computation is statistically bounded by $2MSE(q)$. In practice, both bounds can be computed using Equation (1).
The above approach is still based on exhaustive search. Jégou et al. use an inverted filesystem to circumventexhaustive search. Before using product quantization, the image representations are first quantized into a coarse quantization (with the number of centroids being significantly smaller compared to the product quantization). Each image representation is stored in a list assigned to the corresponding centroid of the coarse quantization. Instead of exhaustive search, only one of these lists is searched for nearest neighbors.
Query Expansion
After retrieving a list of nearest neighbors, several techniques can be employed to improve query results, for example query expansion [4, 3] and spatial verification [1].
Chum et al. bring query expansion, as previously known from text retrieval, to the visual domain. The idea of query expansion is to improve query results by re-issuing a number of highly ranked results as new query to include further relevant results. Average Query Expansion uses the top $K^\ast$ of $K$ retrieved images and averages the corresponding term-frequency (i.e. Chum et al. use the Bag of Visual Words model with term-frequency weighting [1]) representation:
$z_\text{avg} = \frac{1}{K^\ast + 1} \left(z_0 + \sum_{k = 1}^{K^\ast} z_k\right)$
where $z_0$ is the query image and $z_1, \ldots, z_K$ are the retrieved images. The results of query $z_\text{avg}$ is appended to the first $K^\ast$ results of the original query. Usually, this type of query expansion is used in combination with spatial verification such that only verified results are included in the query expansion.
- [1] Josef Sivic and Andrew Zisserman. Video google: A text retrieval approach to object matching in videos. In Computer Vision, International Conference on, pages 1470–1477, Nice, France, October 2003.
References
- [1] J. Philbin, O. Chum, M. Isard, J. Sivic, A. Zisserman. Object retrieval with large vocabularies and fast spatial matching. In Computer Vision and Pattern, Conference on, pages 1–8, Minneapolis, Minnesota, June 2007.
- [2] J. Sivic, A. Zisserman. Video google: A text retrieval approach to object matching in videos. In Computer Vision, International Conference on, pages 1470–1477, Nice, France, October 2003.
- [3] O. Chum, J. Philbin, J. Sivic, M. Isard, A. Zisserman. Total recall: Automatic query expansion with a generative feature model for object retrieval. In Computer Vision, International Conference on, pages 1–8, Rio de Janeiro, Brazil, October 2007.
- [4] R. Arandjelovic, A. Zisserman. Three things everyone should know to improve object retrieval. In Computer Vision and Pattern Recognition, Conference on, pages 2911–2918, Providence, Rhode Island, June 2012.
- [5] H. Jégou, M. Douze, C. Schmid, P. Pérez. Aggregating local descriptors into a compact image representation. In Computer Vision and Pattern Recognition, Conference on, pages 3304–3311, San Fransisco, California, June 2010.
- [6] T. Ge, Q. Ke, J. Sun. Sparse-coded features for image retrieval. In British Machine Vision Conference, Bristol, United Kingdom, September 2013.
- [7] H. Jégou, A. Zisserman. Triangulation embedding and democratic aggregation for image search. In Computer Vision and Pattern Recognition, Conference on, pages 3310–3317, Columbus, June 2014.
- [8] J. Philbin, M. Isard, J. Sivic, A. Zisserman. Descriptor learning for efficient retrieval. In Computer Vision, European Conference on, volume 6313 of Lecture Notes in Computer Science, pages 677–691, Heraklion, Greece, September 2010. Springer.
- [9] A. Oliva, A. Torralba. Modeling the shape of the scene: A holistic representation of the spatial envelope. International Journal of Computer Vision, 42(3):145–175, May 2001.
- [10] K. Mikolajczyk, C. Schmid. Scale and affine invariant interest point detectors. International Journal of Computer Vision, 60(1):63–86, October 2004.
- [11] D. G. Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2):91–110, November 2004.
- [12] H. Jégou, M. Douze, C. Schmid. Product quantization for nearest neighbor search. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(1):117–128, 2011.
- [13] A. Gordo, J. A. Rodríguez-Serrano, F. Perronnin, E. Valveny. Leveraging category-level labels for instance-level image retrieval. In Computer Vision and Pattern Recognition, Conference on, pages 3045–3052, Providence, Rhode Island, June 2012.
- [14] A. Babenko, A. Slesarev, A. Chigorin, V. S. Lempitsky. Neural codes for image retrieval. In Computer Vision, European Conference on, volume 8689 of Lecture Notes in Computer Science, pages 584–599, Zurich, Switzerland, September 2014. Springer.
- [15] R. Arandjelovic, A. Zisserman. All about VLAD. In ´ Computer Vision and Pattern Recognition, Conference on, pages 1578–1585, Portland, Oregon, June 2013.